대학공부/데이터과학
탐색적 데이터 분석(EDA)과 데이터 시각화
진진리
2024. 3. 24. 22:42
728x90
1. 공공데이터 품질 관리와 오류율
데이터 품질 지표(DQI)
- 일관성: 데이터 품질 오류율의 표준 오류율과 직결된
- 세부 지표: 속성 / 표준 / 중복값 / 연계값
- 개체의 속성이 표준을 준수하고 있으며 중복되지는 않는가?
- 데이터 연계에 있어서 일관성이 유지되고 있는가?
- 완전성: 데이터 품질 오류율의 구조 오류율과 직결된
- 세부 지표: 논리 모델 / 식별자 / 물리구조 / 속성의미
- 데이터베이스 구축에 있어 논리적 설계와 물리적 구조가 올바르게 구축되었는가?
- 정확성: 데이터 품질 오류율의 값 오류율과 직결된
- 세부 지표: 입력값 / 업무규칙 / 범위, 형식 / 참조관계 / 계산식
- 데이터가 유효한 범위 및 형식으로 구성되어 있는가?
- 준비성
- 데이터 품질 관리 정책 및 지침이 기관에 맞게끔 잘 정의되어 있는가?
- 경영자 또는 의사결정권자가 데이터 품질 관리 필요성을 이해하고 있는가?
- 보안성
- 데이터베이스 관리 시스템이 정전이나 재해 등에 대비되어 있는가?
- 저작권, 개인정보 등 비공개 대상 정보를 파악하여 관리하고 있는가?
- 적시성
- 데이터 갱신 주기와 방법이 명시적으로 정의되어 있는가?
- 주요 데이터 별 응답시간 기준이 마련되어 있는가?
- 유용성
- 사용자가 만족할 정도의 충분한 정보가 제공되고 있는가?
- 정보 접근을 위한 사용자의 편의성이 충분히 확보되었는가?
데이터 품질 오류율 산정
품질 오류율(%) = 0.7E_값 + 0.2E_표준 + 0.1E_구조
*가중치: AHP 기법으로 결정됨
- 값 오류율: 진단 항목 별 전체 데이터 건수의 합 대비 진단 항목 별 오류 데이터 건수의 합이 가지는 비율
- 표준 오류율: 표준 오류율 측정을 위한 진단 항목 별 오류율의 산술평균
- 구조 오류율: 표준 오류율과 동일한 방법으로 계산
2. 이상치와 결측치에 대한 대응
Boxplot과 Interquartile Range

- Outlier를 제외한 Min, Max
- Whisker: 양 옆에 나와있는 부분
- Q3: 상위 25%
- Q1: 하위 25%
- 왼쪽과 오른쪽 박스에 각각 25%에 해당하는 데이터가 포함됨
- IQR = Interquartile Range = Q3 - Q1
- 주어진 데이터셋 내 데이터의 절반이 IQR의 범위 내에 분포
- Box-and-Whisker 도식을 통해 데이터의 분포를 한눈에 파악할 수 있음
- 평균, 최빈값 등의 통계량을 Box-and-Whisker 도식에서 도출해낼 수는 없음
- Q. 특정 데이터가 이상치에 해당하는지 판단하는 기준은?
IQR을 이용한 이상치 구분

- IQR_A = 40
- IQR_B = 60
- Turkey's Fences
- Q3과 차이가 1.5IQR을 초과할 만큼 큰 값 또는 Q1과 차이가 1.5IQR을 초과할 만큼 작은 값은 이상치로 간주
- A에서 Q3 + 60 초과 혹은 Q1 - 60 미만인 값이 이상치
- Carling's Modification
- Median과 차이가 2.3IQR을 초과하는 값은 이상치로 간주
- B에서 Median과 138 초과하여 차이가 나는 값이 이상치 (198 초과 혹은 -78 미만인 값)
- Q1과 Q3의 위치를 고려하기 어려울 수 있음
정규분포와 3-시그마 규칙

- 3-sigma Rule: 정규분포 하에서 99.7%의 데이터는 평균에서 3σ 내에 위치
- 평균과 3σ 넘게 떨어져 있는 모든 데이터를 이상치로 간주
다 같은 결측치가 아니다

- MCAR(Missing Complete At Random): 결측치가 특정 변수와 관계없이 무작위로 발생한 경우
- 위에서의 Age
- MAR(Missing At Random): 다른 변수와 연관되어 결측치가 발생한 경우
- 위에서의 Lane, Gender가 F일 때 결측치 발생
- MNAR(Missing Not At Random): 변수 스스로와 연관되어 결측치가 발생한 경우
- 위에서의 Tier, 둘 다 Bronze라고 가정했을 때 본인의 티어를 밝히지 않은 경우
삭제를 이용한 결측치 처리
- Column Drop: 결측치가 일정 비율 이상인 열을 제거
- Listwise Delete: 결측치가 하나라도 존재하는 행을 제거
- Pairwise Delete: 분석 모델에 투입되는 열들에 대하여 결측치가 하나라도 존재하는 행을 제거
지우지 말고, 결측치 대체

- 유일한 결측치에 해당하는 데이터의 값을 대체
- 예1) 결측치를 제외한 데이터셋 전체에서 X1 값의 평균으로 대체 (=200)
- 예2) 결측치를 제외한 데이터셋 전체에서 X1 값의 최빈값으로 대체 (=250)
- 문제점?
- 결측치가 발생한 행의 다른 열들을 전혀 고려하지 못함
나와 비슷한 데이터를 닮고 싶다면
- 데이터셋에 존재하는 각각의 데이터들은 2번 데이터와 얼마나 가까울까?

k-최근접 이웃 방법에 기초한 결측치 대체
- 가중치를 고려하지 않는 k-NN 방법을 이용한 결측치 대체
- k=1이면 가장 가까운 이웃의 X1값으로 대체
- k=2이면 가장 가까운 두 이웃의 X1의 평균으로 대체
- 가중치를 고려하는 k-NN 방법을 이용한 결측치 대체
- k=2이면 가장 가까운 두 이웃의 가중 평균으로 대체
- 거리가 가까울 수록 더 큰 가중치를 줌 ex. (a1/d1 + a2/d2) / (1/d1 + 1/d2)
3. shapefile과 지리적 시각화
지리 정보를 한데 모은 shapefile
- shapefile -> 필수 파일
- shp: 기하학적 공간 자료
- dbf: 속성 정보가 담긴 데이터베이스
- shx: 공간 자료와 속성을잇는 색인
- Others
- prj: 투사 및 좌표계 관련 정보
- xml: 공간 메타데이터 포맷
shapefile 정보 기반 DataFrame
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
gdf = gpd.read_file('FILENAME.shp', encoding = 'cp949')- geopandas에서 제공하는 GeoDataFrame은 pandas의 DataFrame과 유사
- 읽기, 수정, 연산 등 DataFrame에서 가능한 대부분의 동작을 공유
- 한글이 포함된 shapefile을 불러오는 과정에서 문제가 발생하는 경우
- encoding 방식을 cp949, euc-kr, utf-8 등으로 변경 후 다시 시도
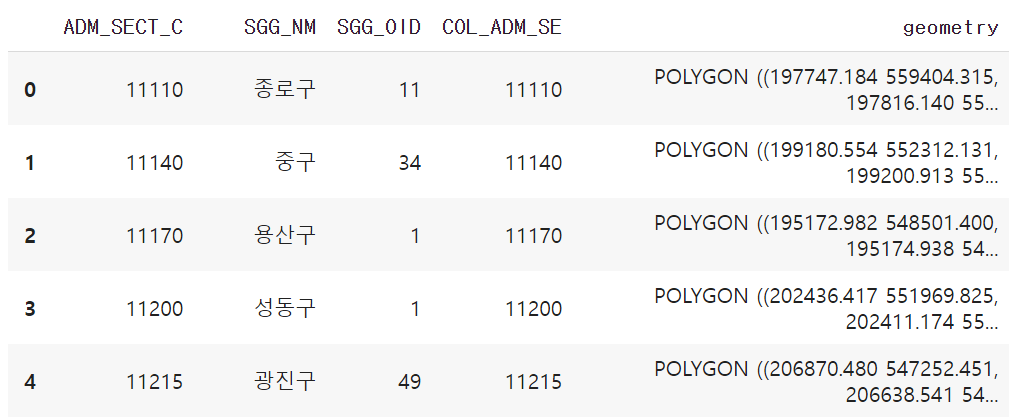
넓이부터 무게중심까지
gdf['geometry'].area
gdf['geometry'].length- area: 준 다각형의 면적을 반환
- length: 준 다각형의 둘레를 반환
- bounds: 준 다각형이 가지는 x, y좌표의 최대-최소 반환
- boundary: 준 다각형의 외부 경계를 LINESTRING 개체로 반환
- centroid: 준 다각형이 가지는 무게중심을 반환
- is_valid: 준 다각형이 유효하게 정의되어 있는지 반환
서울특별시 25개 자치구를 시각화하면?
gdf = gpd.read_file('LARD_ADM_SECT_SGG_11_202403.shp', encoding = 'cp949')
gdf.plot(figsize = (20, 40), color = 'lightgray', edgecolor = 'black', linewidth = 2)
plt.show()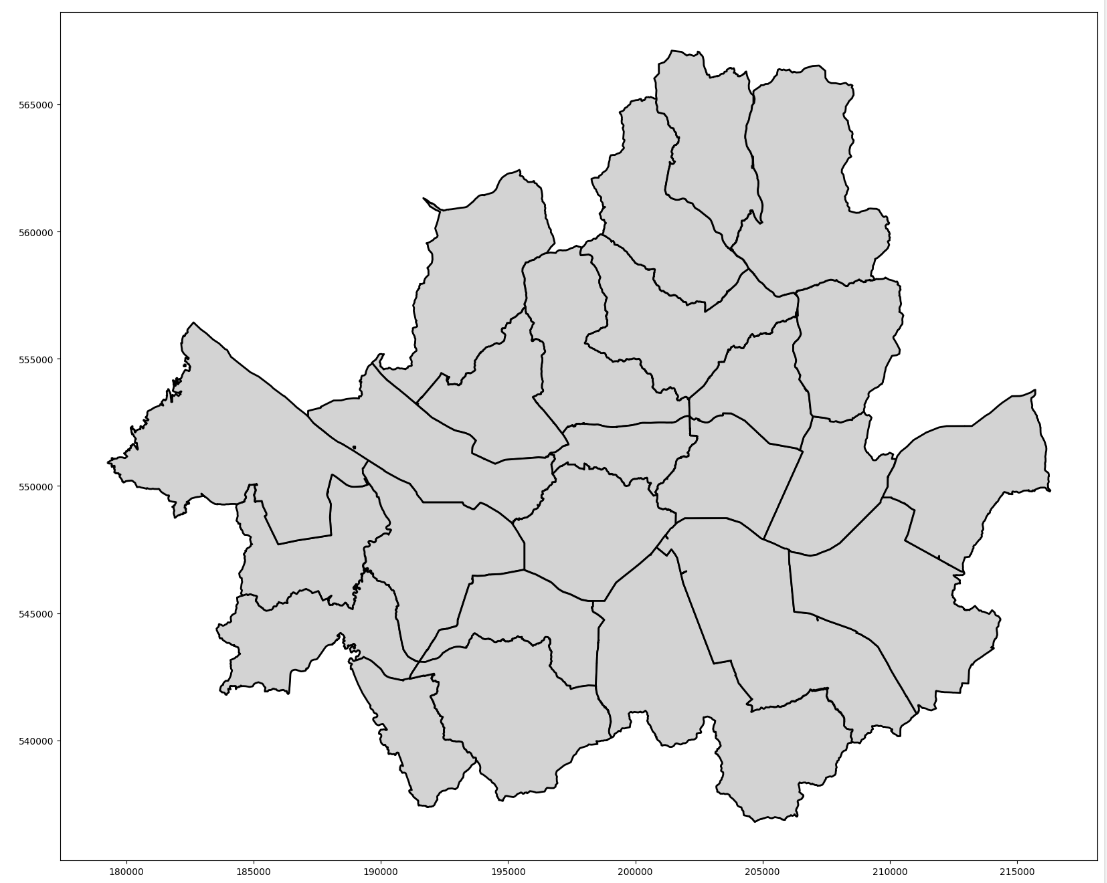
잠깐, DataFrame과 똑같다면...
dust.csv를 이용해 미세먼지 농도가 높은 구일수록 진한 색으로 표시하면?
- GeoDataFrame 내 오탈자 수정 및 dust.csv와의 merge
gdf.iloc[9, 1] = '도봉구' # 기존 값은 '서울시도봉구', '서울시노원구'이기 때문에 변경
gdf.iloc[10, 1] = '노원구'
df = pd.read_csv('dust.csv', encoding = 'cp949')
gdf = gdf.merge(df, how = 'left', on = 'SGG_NM') # SGG_NM은 구 column명- 기준 column 설정 및 cmap 도식화
gdf.plot(figsize = (20, 40), column = 'SGG_NM', cmap = 'OrRd')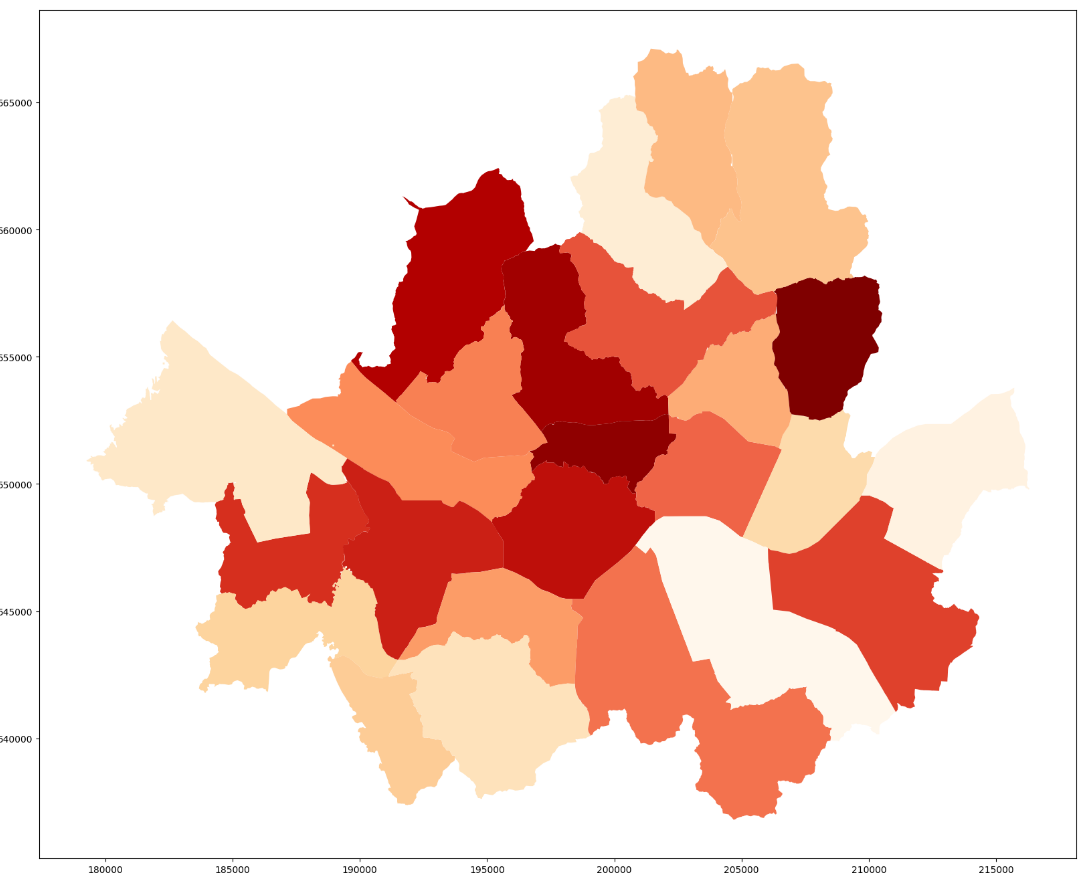
plot 위 또 다른 plot
# TG_ACDT19 어린이구역에 대한 shapefile
gdf_child = gpd.read_file('TG_ACDT19.shp', encoding = 'utf-8')
ax1 = gdf.plot(figsize = (20, 40), color = 'lightgray', edgecolor = 'black', linewidth = 2)
gdf_child.plot(ax = ax1)
plt.show()- gdf의 정보를 이용하여 1차 시각화, gdf_child의 정보를 이용하여 2차 시각화
- 지리적 시각화에서 plot 중첩 시 유의점은? 축을 고정할 필요가 있음
4. 좌표계 변환과 folium의 활용
주요 지표계의 종류와 특성
- 지리 좌표계: 지구를 3차원 타원체로 간주해 대상의 위치를 나타내는 좌표계
- 위도(Latitude)와 경도(Longitude) 이용, 원하는 좌표를 표현
- 도-분-초 형태의 DMS와 소수 형태의 Degree로 구분
- 1분은 (1/60)도이며 1초는 (1/3600)도에 해당함
- 평면직각 좌표계: 경위도를 평면 위에 투영해 대상의 위치를 나타내는 좌표계
- (TM) 중부, 동부, 서부, 동해 등 네 가지 투영 원점이 가능
- (UTM-K) 동경 127.5º 북위 38º 위치를 원점으로 삼음
- Q. UTM-K 좌표계가 갖는 원점을 DMS 형태로 표기하면?
- 127분 30분 0초, 38도 0분 0초
EPSG와 좌표계 구분
- EPSG(European Petroleum Survey Group)
- EPSG 코드 값을 이용해 주어진 데이터셋이 어떤 좌표계를 활용하는지 파악
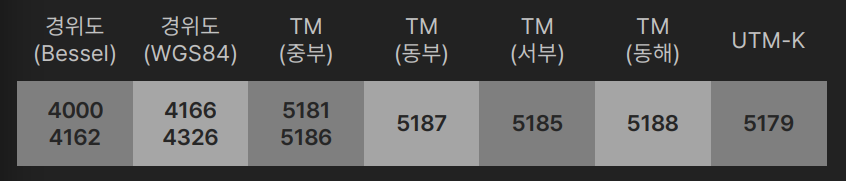
경위도에서 TM으로, 또 그 반대로
- GeoDataFrame에 to_crs를 적용하여 좌표계 변환 가능
new_gdf = gdf.to_crs(epsg = 4326) # 5186 -> 4326
new_gdf
서울 지하철 2호선의 모든 정차역은
- Folium을 이용한 서울특별시 지하철 2호선 정차역 시각화
import folium # 지도맵을 가져와서 시각화
from folium import Marker
m = folium.Map(location = [37.57, 126.98], # 중심부 - 시청
tiles = 'openstreetmap', zoom_start = 15)
df_subway = pd.read_csv('subway.csv', encoding = 'cp949')
for i in range(0, len(df_subway)) :
lati = df_subway.iloc[i, 4]
longi = df_subway.iloc[i, 3]
station_name = df_subway.iloc[i, 2]
new_marker = Marker(location = [lati, longi], popup = station_name)
new_marker.add_to(m)
m
- Map 생성 시 tiles로 지도의 스타일을, location으로 중심을 바꿀 수 있음
- 데이터셋에 담긴 좌표 정보가 위경도 형태가 아닐 경우 사전 변환을 거쳐야 함