대학공부/자연어처리
자연어처리 task
진진리
2024. 3. 27. 17:16
728x90
자연어처리 모델의 학습 방법
- 트랜스퍼 러닝(Transfer Learning): 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법
- 특징
- 기존보다 모델의 학습 속도가 빨라짐
- 새로운 태스크를 더 잘 수행

업스트림(Upstream) 태스크
- 모델이 대규모의 코퍼스를 가지고 문맥을 고려하면서 태스크 수행
- 대표적인 업스트림 태스크
- 다음 단어 맞히기
- 빈칸 채우기(BERT-Masked Language Model)
- GPT 계열 모델
다운스트림(Downstream) 태스크
- 자연어처리의 구체적인 태스크 성능을 올리기 위해 (업스트림 태스크로 Pre-training)
- 다운스트림 태스크의 본질은 Classification
- 자연어를 입력받아 해당 입력이 어떤 범주에 해당하는지 확률 형태로 반환
- 문서분류, 자연어추론, 개체명인식, 질의응답, 문장생성 등
자연어처리 학습 과정
- 자연어처리 모델을 만들려면?
- 코퍼스(데이터)를 준비
- 모델이 데이터의 패턴을 스스로 학습하게 함
- 학습: 출력이 정답에 가까워지도록 모델을 업데이트하는 과정
- 태스크 학습 과정


다운스트림 태스크
1. 개체명 인식 (NER, Named Entity Recognition)
- 사람(Person, PS), 장소(Location, LC), 기관(Organization, OG), 날짜(Date, DT) 등과 같은 명명된(named) 객체를 텍스트로 식별하는 작업
- 질의 답변, 정보 검색, 관계 추출 등을 위한 NLP 시스템의 핵심 구성 요소
- 예시1) 춘향[PS]아, 8월 15일[DT]에 강남[LC]에서 홍길동[PS]과 약속이 있으니까, 늦지 말고 오도록 해!
- 예시2) 명량 대첩은 1597년[DT] 음력 9월 16일[DT] 정유재란[DT] 때 이순신[PS]이 지휘하는 조선 수군 13척이 명량[LC]에서 일본 수군 130척 이상을 격퇴한 해전이었다.
- NER은 도메인의 특성에 많이 영향을 받음, 명사를 잘 인식하는 것이 중요한 문제.

- 개체명 인식을 하는 이유
- 정보검색
- 번역의 품질 향상(오류 감소)
- 질의응답
- 지식베이스 구축
- 지도학습 기반 시스템
- 은닉 마르코프 모델(HMM) -> 가장 성능이 좋음
- 서포트 벡터 머신(SVM)
- 조건부 무작위(CRF)
- 대문자, 트리거 단어, 이전 태그 예측, 단어 모음, 사전 등과 같은 자질을 사용하여 NER 성능을 높일 수 있음
- 한국어의 경우 - 형태소 정보
- 지식 기반 시스템
- 사전에 없는 어휘가 많이 존재하는(Out of Vocabulary, OOV) 시스템에서 효과를 발휘하기 어려움
- 정확도(accuracy)는 일반적으로 높을 수 있으나, 도메인 및 언어 별 규칙과 사전의 불완전성으로 recall 값은 낮음
- 도메인 전문가가 필요함
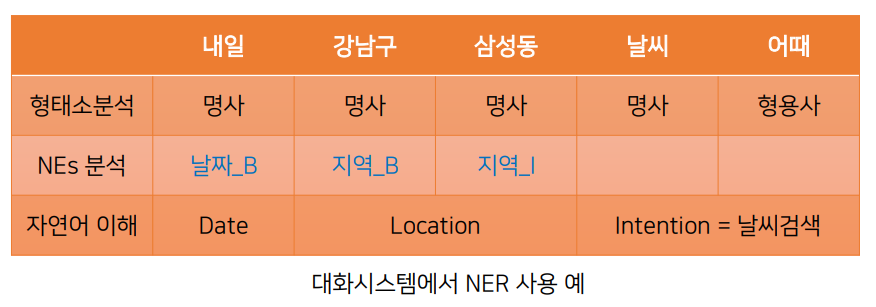
BIO Tagging Scheme
- BIO 태깅 기법
- 개체명을 텍스트로부터 인식시키기 위한 기법 중 하나로 정보 추출 작업에서 자주 이용됨
- B(Begin): 개체명 중 시작을 나타내는 단어에 태그
- I(Inside): B 혹은 I 개체명 뒤에 오는 단어에 태그
- O(Outside): 개체명이 아닌 나머지 단어에 태그
- 개체명을 텍스트로부터 인식시키기 위한 기법 중 하나로 정보 추출 작업에서 자주 이용됨
학습 코퍼스 - 대표적인 말뭉치
- CHEMDNER
- Drug NER shared task: 의약품, 브랜드 및 신약과 같은 의약품 개체명을 중심으로 생성
- Twitter
- 사람, 회사, 시설, 스포츠팀, 영화 TV쇼 등의 개체명이 존재
- 문법적으로 불완전하거나 구어체 문장을 포함하고 있어 성능 저하의 주된 원인으로 꼽힘
NER 평가 척도
- 오차 행렬(Confusion matrix): 행렬을 통해 이진 분류의 예측 오류를 나타내는 지표

- 정밀도(Precision): TP / (FP + TP), 예측이 Positive인 것 중에서 참인 것의 비율
- 재현율(Recall): TP / (FN + TP), 실제값이 Posifive인 것 중에서 참인 것의 비율
- F1 스코어(F1-score): 정밀도와 재현율을 결합한 평가 지표
- 정밀도와 재현율이 상충 관계인 문제점을 고려하여 정확한 평가를 위해 많이 사용

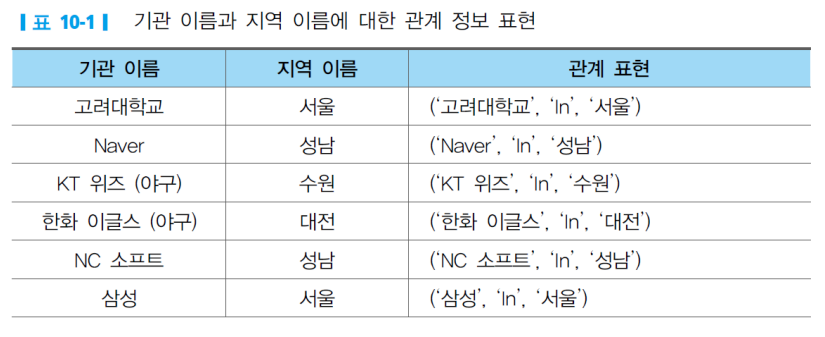
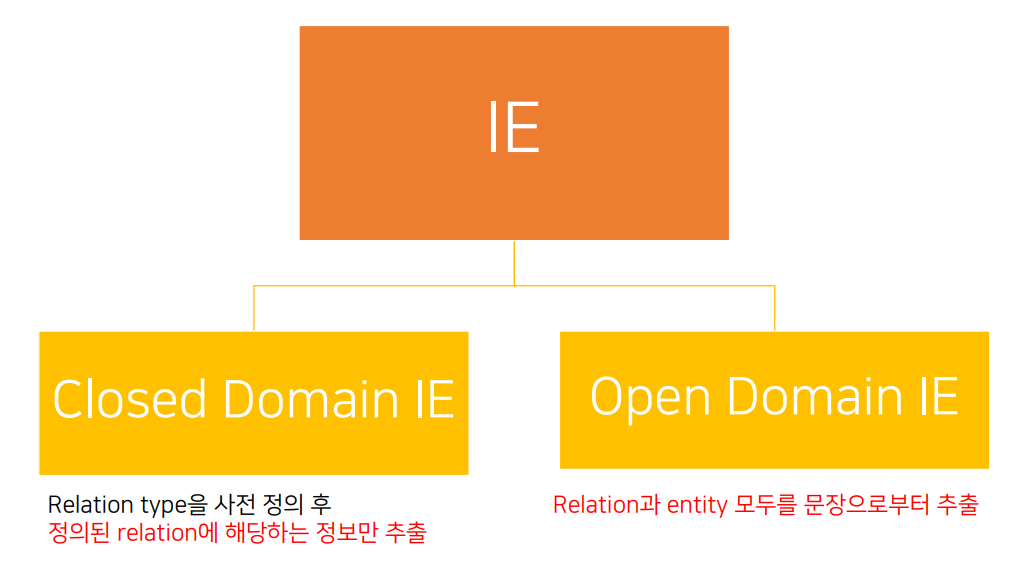
2. 정보추출(IE, Information Extraction)
- 비정형 또는 정형화된 텍스트에서 자동으로 구조화된 정보를 추출하는 작업
- 비정형 텍스트에서 정보 추출하기 위해 규칙적이고 엔티티 간의 의미적 관계를 포함하는 구조화된 데이터가 필요함
- 목적: 문서 내 단어 간의 대상 관계를 파악하여 의미적 관계를 추출하고 이에 대해 응답하는 것을 중점을 둠
- 관계형 튜플(triple) 표현
- (Entity 1, Relation, Entity 2)
- (Subject, Predicate, Object)
정보추출 시스템의 구분
정보 추출의 학습 방법
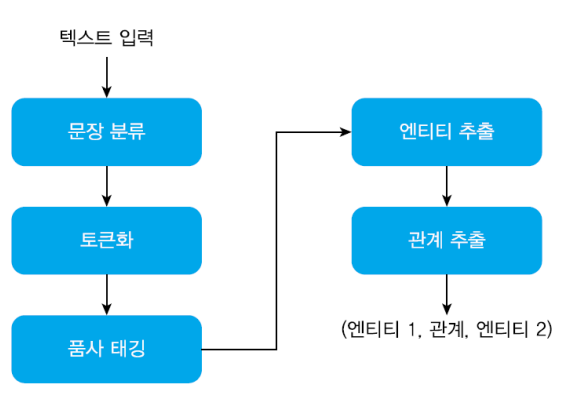
- 입력된 문서를 문장 단위로 분할
- 각 문장을 토큰화
- 품사 태깅을 통해 단어의 품사를 파악
- 품사를 기준으로 해당 엔티티를 추출하여 label(보통 명사구, 술어 기준) 지정
- 엔티티 쌍 사이의 특정 패턴을 찾음
- 튜플 형식으로 결과를 출력
정보 추출의 주요 하위 작업
- NER(Named Entity Recognition)
- 상호 참조(Coreference Resolution)
- 관계 추출(Relation Extraction)
- 각 엔티티의 유형을 감지하여 엔티티 간의 관계를 식별하고 유형을 추출하는 것이 목표
정보 추출(관계 추출)의 접근법
- 규칙기반 접근법
- 문법적 속성에 대한 규칙 세트를 정의한 다음 규칙을 사용하여 정보를 추출
- 대표적인 library로 spaCy 사용: Tokenization, 품사 태깅, 개체 인식 등 기본적인 전처리 기능을 지원
- 기계학습 기반 접근법
- Superviced learning: 모델을 훈련시키기 위해 많은 label된 데이터가 필요
- Semi-superviced learing: Label된 데이터가 충분하지 않을 때 seed example(triple)을 사용하여 더 많은 관계를 추출할 수 있는 high-precision pattern을 구성할 수 있음
3. 텍스트 분류 (문서 분류)
- 텍스트 분류
- 문장 또는 문서를 입력으로 받아 사전에 정의된 클래스 중에 어디에 속하는지 분류(Classification)하거나 각 데이터를 군집화(Clustering)하는 과정
- 분류(Classification): 지도학습에 속하며, 자료를 항목에 맞게 범주화하는 작업
- 군집화(Categorization): 비지도학습에 속하며, 정해진 항목이 아닌 유사 관계에 의하여 분류
다양한 텍스트 분류 예시
- 카테고리 및 의도 분류
- 스팸 메일 분류
감정분석이란 무엇인가
- 감정분석: 문장 또는 지문의 감정을 분석하는 것
- 규칙 기반 모델이나 확률 모델, 딥러닝 모델
- Sentiment Analysis vs Emotion Analysis
- 감정 - 긍정/부정, 감성 - 즐거움/우울함 등
텍스트 분류 프로세스
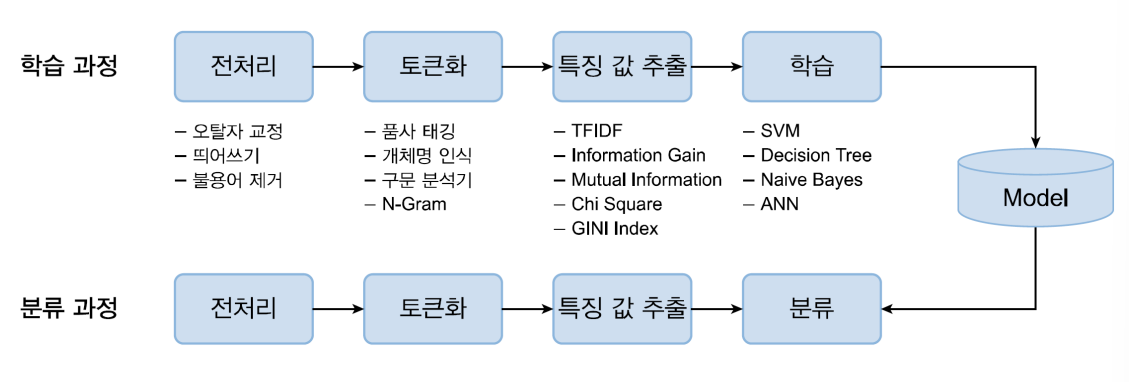
- 특징 값 추출
- Bag of Words: 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도에만 집중하는 텍스트 수치화 표현 방법
- TF-IDF: 단어의 빈도와 역문서 빈도를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법
- 대표적인 분류 알고리즘
- Naive Bayes Classifier
- SVM
- KNN, Decision Tree, The Random Forest Algorithm
- 군집화: K-means algorithm
다른 다양한 태스크
- 자연어처리 태스크: https://nlpprogress.com/
- 데이터 및 논문: https://paperswithcode.com/
- 자연어 추론, 질의 응답, 문장 생성
딥러닝 소개
딥러닝의 개요
- 인공지능: 주변 환경을 인식하고 이로부터 목표를 성취할 가능성을 최대화하는 일련의 행동들을 계획할 수 있는 알고리즘 및 장치를 개발하는 것이 목표
- 기계학습: 인공지능의 하위 분야로, 목표에 대한 명시적 프로그래밍 없이도 이를 수행할 수 있는 알고리즘을 학습하는 것이 목표
- 딥러닝: 기계학습의 하위 분야로, 두뇌를 모방한 인공신경망 구조를 가진 다양한 계층을 조합하여 데이터로부터 목표를 수행할 수 있는 방법을 학습할 수 있는 알고리즘을 개발하는 것이 목표
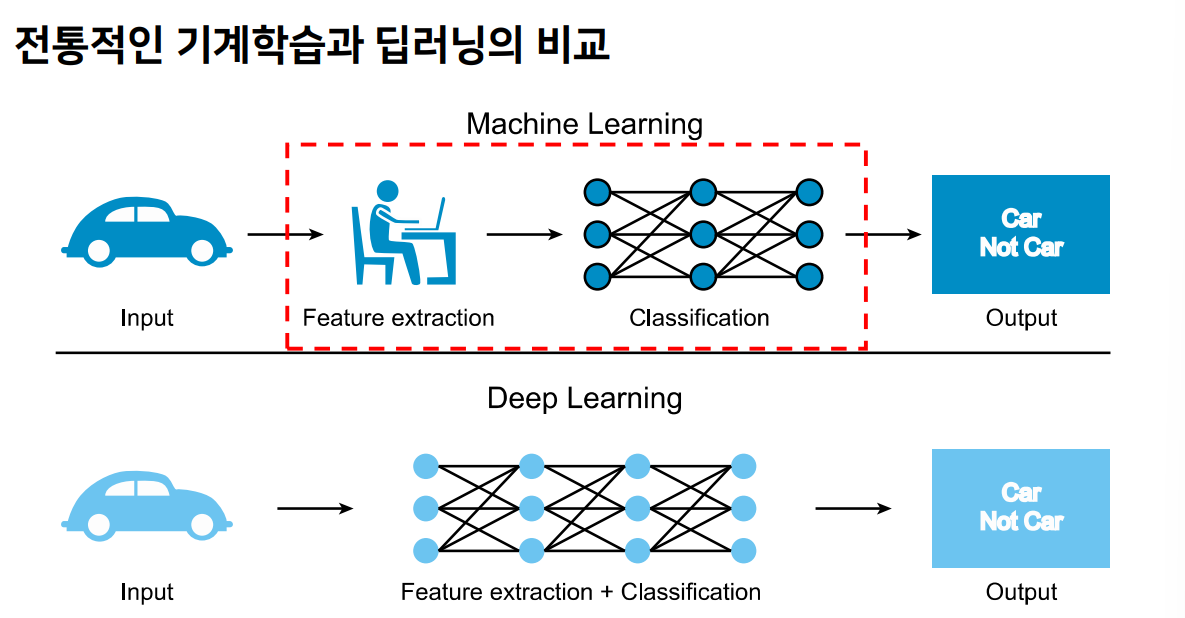
규칙 기반 vs 통계 기반 기계학습 비교
- 규칙 기반 모델
- 적은 양의 데이터로 일반화 가능
- 전문가의 오류를 동일하게 반복
- 규칙 구축에 많은 시간과 비용 소요
- 통계/딥러닝 기반 모델
- 데이터의 질이 좋고 양이 많으면 인간을 넘어설 수 있음
- 결과에 대한 해석이 어려움
자동적인 계층적 자질 표상 습득
- 자질 표상(Feature Representation): 모델이 목적을 잘 수행할 수 있도록 도움을 주는 입력의 특징들
- 딥러닝 모델은 자동적으로 자질 표상을 생성
딥러닝 시스템 구축: 데이터와 모델 구조
- 딥러닝 모델
- 전문가 지식의 필요성 감소
- 학습에 필요한 데이터 양은 기하급수적으로 증가
- 학습에 사용한 데이터의 양과 질에 비례하여 성능이 결정됨
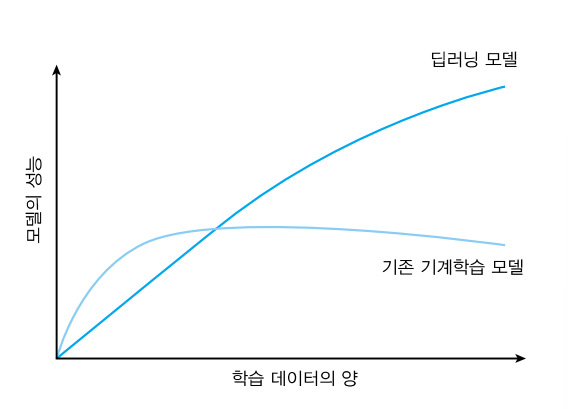
데이터의 용도: 지도학습용 vs 비지도학습용
- 지도학습
- 정답(레이블)을 필요로 하는 데이터
- 시간 및 금전적 비용 발생
- 대량으로 구축하기 어려움
- 비지도학습
- 정답(레이블)이 필요하지 않은 데이터
- 손쉽게 대량으로 구축 가능
모델 구조 선택
- 입력과 출력의 (수)특성을 파악하는 것이 중요
- 예) 입력 혹은 출력이 단일 혹은 고정 개수일 경우 완전연결층 (FCN) 혹은 합성곱 신경망 (CNN)을, 가변 개수일 경우 순환 신경망 (RNN)을 사용
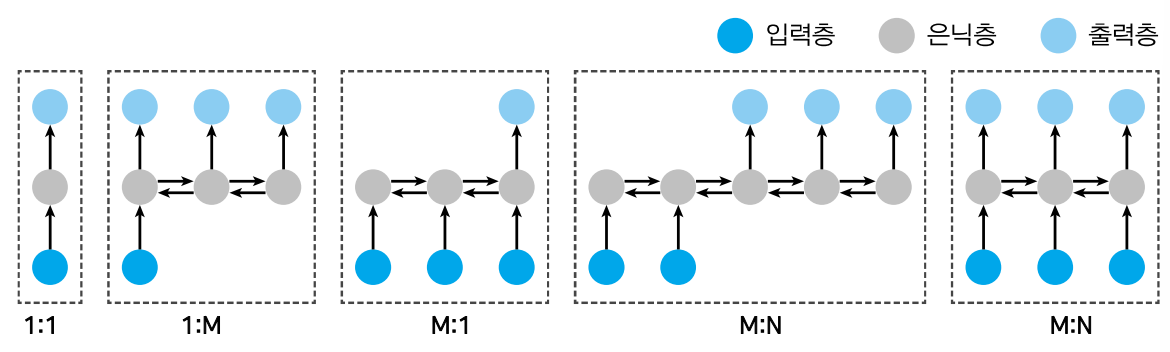
딥러닝 모델의 뼈대: 퍼셉트론
- 각각의 입력 값에 가중치를 곱한 후 이 값들과 편향 값을 더하여 1차 출력을 만듦
- 퍼셉트론의 결정 경계 (Decision boundary): 선형
- y = x1 * w1 + x2 * w2 + w0
퍼셉트론을 이용한 딥러닝 모델의 구성
- 입력층(input layer): 입력 데이터를 받아들이는 계층
- 출력층(output layer): 결과를 출력하는 계층
- 은닉층(hidden layer): 입력층과 출력층 사이의 계층들
비선형 결정 경계
- 계층의 수가 증가할수록 결정 경계의 구조도 복잡해짐
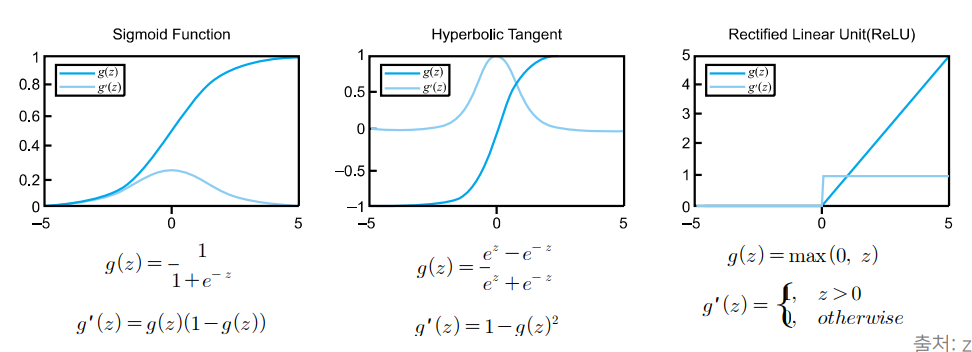
활성 함수 (Activation Function)
- 신경망이 비선형 분류를 할 수 있도록 해줌
- sigmoid, tanh, ReLU가 가장 많이 쓰임
- 함수의 특징을 결정짓는 것은 출력값과 미분값이며, 출력값은 출력 특성에, 미분값은 계층의 학습 특성에 영향을 미침
딥러닝 모델의 학습
- 수많은 파라미터들의 최적값을 찾아가는 과정
- 입력에 대해 모델이 예측을 하고 예측과 정답 사이의 차이를 감소시키도록 학습
- 정방향 계산(forward pass): 입력으로부터 예측을 만들어내는 과정
- 역방향 계산(backward pass): 예측과 정답 사이의 차이를 줄이는 방향으로 파라미터를 수정하는 과정
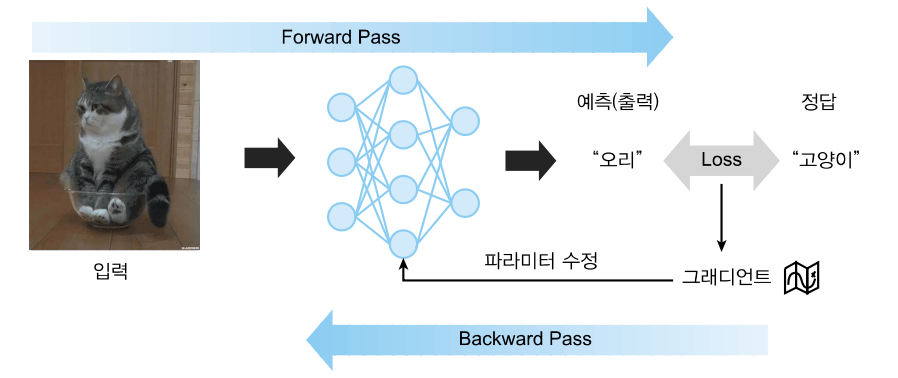
- 손실 함수(loss function): 모델의 예측과 정답 사이의 차이를 수치화시켜주는 함수
- 역전파(back-propagation): 출력에서 입력으로 계산이 역방향으로 진행됨. 미분이 불가능할 때까지
Pre-train Language Models (PLMs)
배경
- 딥러닝의 발달로 모델의 파라미터 수가 급격히 증가
- 구문 및 의미론적으로 관련된 작업에 많은 labeling 비용 발생
Pre-training 장점
- universal language representations을 배울 수 있고, Down-stream task에 도움을 줄 수 있음
- 더 좋은 Initialization을 가능하게 하며 이는 더 나은 generalization으로 이어짐
- 작은 데이터에 대한 Over-fitting을 피하기 위한 일종의 regularization
Transfer Learning: source task에서의 지식을 target task로 전달하는 것
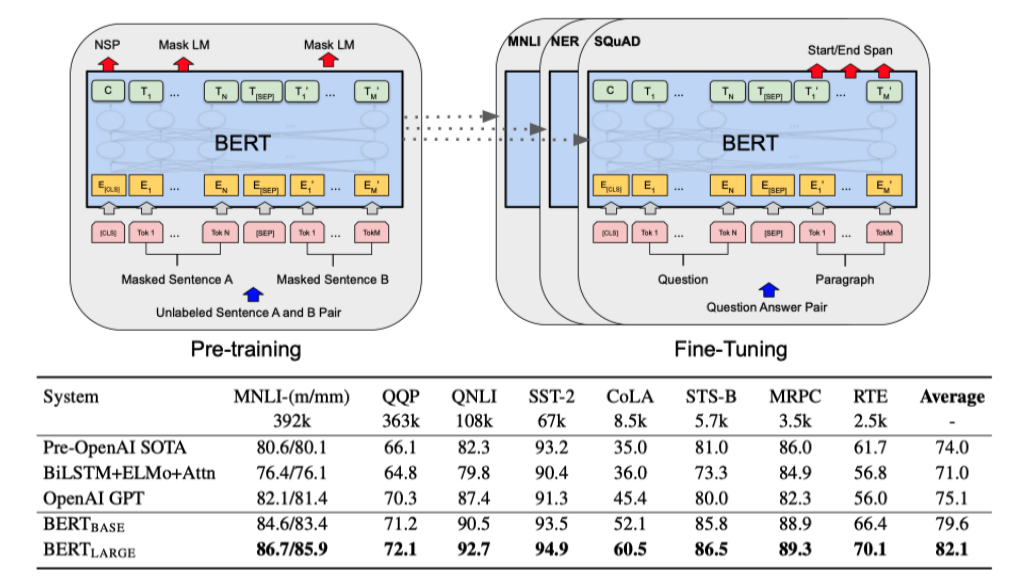
BERT
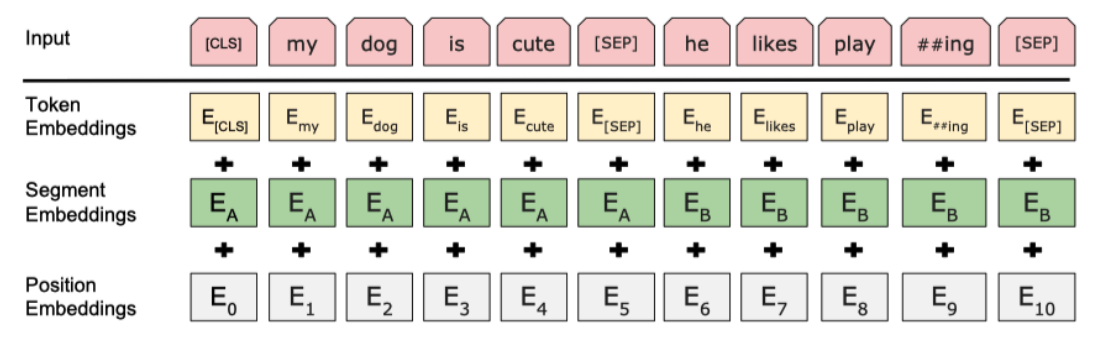
- 문장의 시작을 CLS, 끝은 SEP
- SEP 토큰을 문장 간 구별을 위해 사용 (Segment Embeddings)
Pre-Training: MLM(Masked Language Model)과 NSP(Next Sentence Prediction)을 제시 -> 문맥적 이해가 가능
- MLM: 15%로 random하게 Making해서 학습, 나머지를 예측 -> 문맥을 파악하는 능력 학습
- NSP: 두 문장 사이의 관계를 이해하는 것을 학습
- 50%는 이어지는 문장들
- 50%는 관계없는 문장들
- 11가지의 Down-stream task에서 좋은 성능을 보임 -> 언어적인 문맥, 의미를 잘 이해
ChatGPT
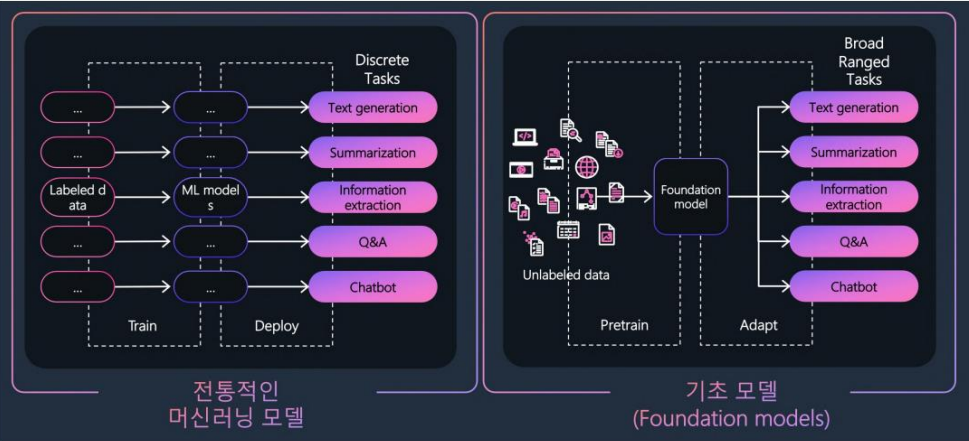
- LLM(Large Langue Module): 하나의 모델을 잘 만들면 다른 태스크들도 다 잘 수행
Generative AI란?
- 사용자의 요구사항에 따라 새로운 컨텐츠를 생성해주는 AI. 학습된 추론 및 의사결정 능력으로 새로운 결론 및 컨텐츠 생성
GPT(Generative pre-trained transformer)
- 자연어처리 기반이 되는 조건부 확률 예측 도구
- 데이터를 많이 넣고 그 다음 단어를 예측하는 태스크를 학습
- GPT-1 : 자연어처리(NLP) 태스크에서 좋은 성능을 보임
- GPT-2 : QA 모델의 기초가 됨 (질의응답에 뛰어남)
- GPT-3 : 파라미터 수를 늘림 -> 새로운 태스크에 대해서도 fine-tuning 없이 바로 사용이 가능함
- GPT-4 : 파라미터 수를 늘림, 다양한 데이터를 함께 사용
ChatGPT 학습 방법
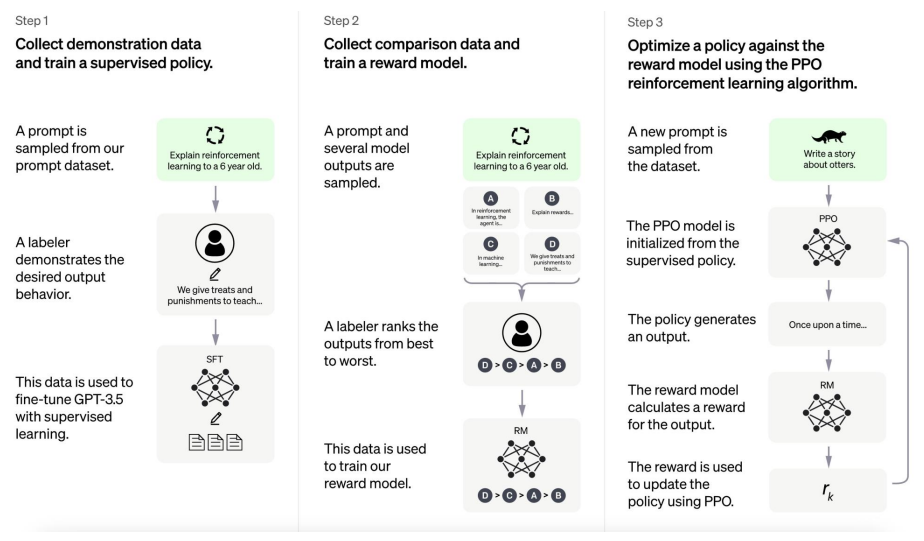
데이터의 질을 높임
step1. 데이터 구축
step2. 질문하고 4가지 답변을 사람이 순서를 정렬
step3. 강화학습을 통해 학습
현재 실시간적인 답변은 못함 (예. 지금 몇 시야?)
GPT-3의 변화: Few-shot
- 엄청난 스케일의 모델 파라미터
- Few-shot learning: 몇 개의 예시들만 학습하면 다음을 잘 맞추게 됨
- 파라미터의 수가 많을 수록 훨씬 성능이 좋음
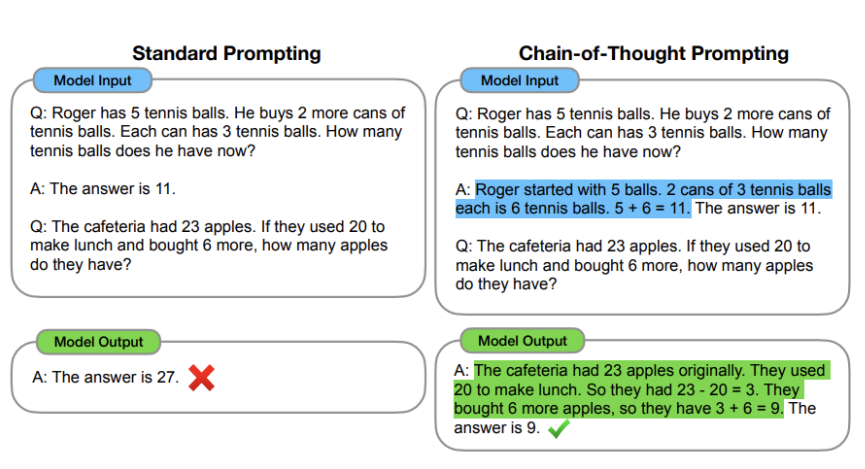
- Chain-of-Thought(CoT) Prompting: 사람의 사고 방식대로 질문하면 성능이 높아짐
- zero-shot에서도 성능을 보임. 예) Let's think step by step
Prompt Basic Components
- Role: 역할 부여
- Audience: 대화 대상자
- Knowledge(Information): 유명한 출처 정보를 지정
- Task: 목표를 명확히 지정
- Style: 언어 스타일
- Constraint: 특정 제한 사항
- Format: 데이터 형식
- Examples: 원하는 응답 예시 제시