대학공부/데이터과학
의사결정나무를 이용한 분류와 예측
진진리
2024. 4. 1. 17:39
728x90
1. 정규화와 회귀에 대한 평가
선형 회귀 식, 데이터에 얼마나 걸맞나
- R^2 (R-squared, 결정계수)
- 종속 변수의 변동 중 몇 퍼센트만큼을 이 회귀 모형이 설명할 수 있는가?
- 독립 변수를 더 다양하게 투입할 수록 값이 늘어나는 경향을 띔
- 관계가 없는 속성을 독립변수로 추가할 때에도 R^2 값이 증가
- adjusted R^2 (adjusted R-squared, 수정된 결정계수)
- N: validation set의 데이터 개수, p: 독립 변수의 개수
- 독립 변수의 개수가 많아져도, 무작정 R^2이 증가하지 않음

성능 지표 계산을 위한 라이브러리
# 성능 지표 계산을 위해 필요한 라이브러리 불러오기
from sklearn.metrics import r2_score # 결정계수
from sklearn.metrics import mean_squared_error # 평균제곱오차
from sklearn.metrics import mean_absolute_error # 평균절대오차
# 선형 회귀에서의 결정계수 출력
r2_score(y_valid, y_pred)
선형 회귀 식의 MSE 값 확인하기
mean_squared_error(y_valid, y_pred)- RMSE(Root Mean Squared Error, 평균제곱근오차)
- MSE의 제곱근, 즉 오차 제곱의 평균을 구해 제곱근을 취한 값
- 오차가 큰 데이터인 경우 MSE 대신 사용
- MSE와 RMSE의 문제점은?
- 절대 지표이므로, MSE만 가지고 예측 모델의 성능을 비교할 수 없음
이제는 값에서 비율로, MAPE
- MAPE(Mean Absolute Percentage Error, 평균절대비율오차)
- 실제 값 대비 오차의 비율들을 계산하여 평균을 낸 값

- 갑: (250-200) / 250 = 20%
- 을: 15 / 300 = 5%
- 병: 60 / 240 = 25%
- 정: 20 / 200 = 10%
- 평균: 60 / 4 = 15%
Exercise 1.
RMSE = 200
학습 데이터의 크기(N) = 55
과적합 문제 해결을 위한 두 가지 접근
- 독립 변수의 종류를 줄인다.
- 선형 회귀 식에서 불필요한독립 변수를 제거
- Feature Selection을 위한 Algorithm?
- 계수 Θ의 값을 줄인다.
- 회귀 식에서 계수 Θ의 크기를 줄여 독립 변수의 영향력을 낮춤
- 정규화 Regularization
선형 회귀의 궁극적 목표는 무엇이었나?
- 선형 회귀니까 평균제곱오차 MSE를 줄이고...
- 과적합은 피하기 위해 계수 Θ 값들도 전체적으로 줄이고...

- ||Θ||1 : |Θ1| + |Θ2| + |Θ3| + ...
- ||Θ||2 : 루트(Θ1^2 + Θ2^2 + Θ3^2 + ...)
- α : 정규화 가중치 -> α 값이 작으면 MSE(첫 번째 목표)에 집중하게 됨
Lasso 정규화 => 최소화(MSE + |Θ0| + |Θ1| + ... + |Θn|) :: 둘을 절충함
Ridge 정규화 => 목표는 똑같으나 절대값이 아닌 제곱한 값을 사용
sklearn을 이용한 정규화 수행
- sklearn에서의 Lasso Regularization
# sklearn에서의 Lasso Regularization
from sklearn.linear_model import Lasso
reg_Lasso = Lasso(alpha = 0.5)
reg_Lasso.fit(x_train, y_train)
y_pred_Lasso = reg_Lasso.predict(x_valid)- sklearn에서의 Ridge Regulaization
# sklearn에서의 Ridge Regularization
from sklearn.linear_model import Ridge
reg_Ridge = Ridge(alpha = 0.5)
reg_Ridge.fit(x_train, y_train)
y_pred_Ridge = reg_Ridge.predict(x_valid)
서로 다른 두 정규화 방식, 원리의 차이는

- Lasso: 2차원 상에서 마름모 모양
- 타원을 평행이동 할 때 마름모의 꼭짓점에 맞닿게 됨 (x값이 죽고 y값만 남아있게 됨)
- Ridge: 2차원 상에서 원 모양
- 타원을 평행이동할 때 x와 y를 절충한 곳에 닿게 됨
- Lasso의 경우, Θ 중 몇 가지가 사라짐 -> 변수의 선택
- Ridge의 경우, 모든 Θ가 완전히 죽지 않도록 함 -> 가중치 분배
둘을 절충한 것이 엘라스틱 넷
2. 의사결정나무와 분류 문제 해결
의사결정나무 구조에 숨은 분류의 원리
- 나무의 Root Node에서 출발하여 Leaf Node에 이르기까지 분기를 수행
- 분류 성능은 분기의 기준에 달려 있는데, 어떻게 분기의 기준을 결정하나?
불순도를 나타내는 두 가지 지표
- Gini Index
- 1 - (각 항목이 차지하는 비율의 제곱 합)
- 항목이 두 가지일 경우 값의 범위는 0 ~ 0.5(반반일 때 가장 높음)
- Entropy
- -∑pi log2pi
- 항목이 두 가지일 경우, 값의 범위는 0 ~ 1
불순도를 최대한 낮게, 의사결정나무
의사결정나무(Decision Tree)
- 불순도가 낮아지는 방향으로 주어진 데이터를 분류하는 분석 방법
- 어떤 불순도 지표를 택할지, 어떻게 분류할지에 따라 생성 방식이 상이
- 예1) CART(Classification And Regression Tree) - 지니 계수에 기초하여 DT를 생성하는 알고리즘
- 예2) CHAID(Chi-squared Automatic Interaction Detection)
CART 분류 나무를 만들어보면?

CASE 1 : 5G 사용 여부
사용 그룹 Gini = 1 - (4/25 + 9/25) = 12/25 = 0.48
비사용 그룹 Gini = 1 - (0 + 1) = 0
가중 평균을 고려하여 Gini = 5/7 * 0.48 + 2/7 * 0 = 약 0.343 (= 12/35)
CASE 2 : 청년 여부
청년 그룹 Gini = 1 - (1/9 + 4/9) = 4/5 = 0.8
비청년 그룹 Gini = 1 - (1/16 + 9/16) = 0.6
가중 평균을 고려하여 Gini = 3/7 * 0.8 + 4/7 * 0.6 = 약 0.686
CASE 3: 문의 이력 여부
문의 그룹 Gini = 0
비문의 그룹 Gini = 1 - (4/25 + 9/25) = 12/25 = 0.48
가중 평균을 고려하여 Gini = 5/7 * 0.48 = 약 0.343 (= 12/35)
Python에서의 의사결정나무 생성
- graphviz 설치 과정 수행
!pip install graphviz # DT 결과 시각화- 주요 라이브러리 불러오기
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz- DataFrame 제어
df = pd.read_excel('telecom.xlsx')
df = pd.get_dummies(df, columns = ['Technology']) # 각 범주에 맞는 데이터가 만들어짐 (입력 변수를 수치형 변수로)
df_x = df.iloc[:, [0, 1, 2, 4, 5, 6, 7]]
df_y = df['Leave']- 의사결정나무의 생성
tree_model = DecisionTreeClassifier(criterion = 'gini', max_depth = 3, min_samples_leaf=5)
tree_model.fit(df_x, df_y)- graphviz를 이용한 시각화
# 시각화를 위한 소스, tree_model을 바탕으로 시각화
dot_data = export_graphviz(tree_model, out_file = None, feature_names = df_x.columns,
class_names = tree_model.classes_, filled = True, rounded = True, special_characters = True)
graph = graphviz.Source(dot_data)
graph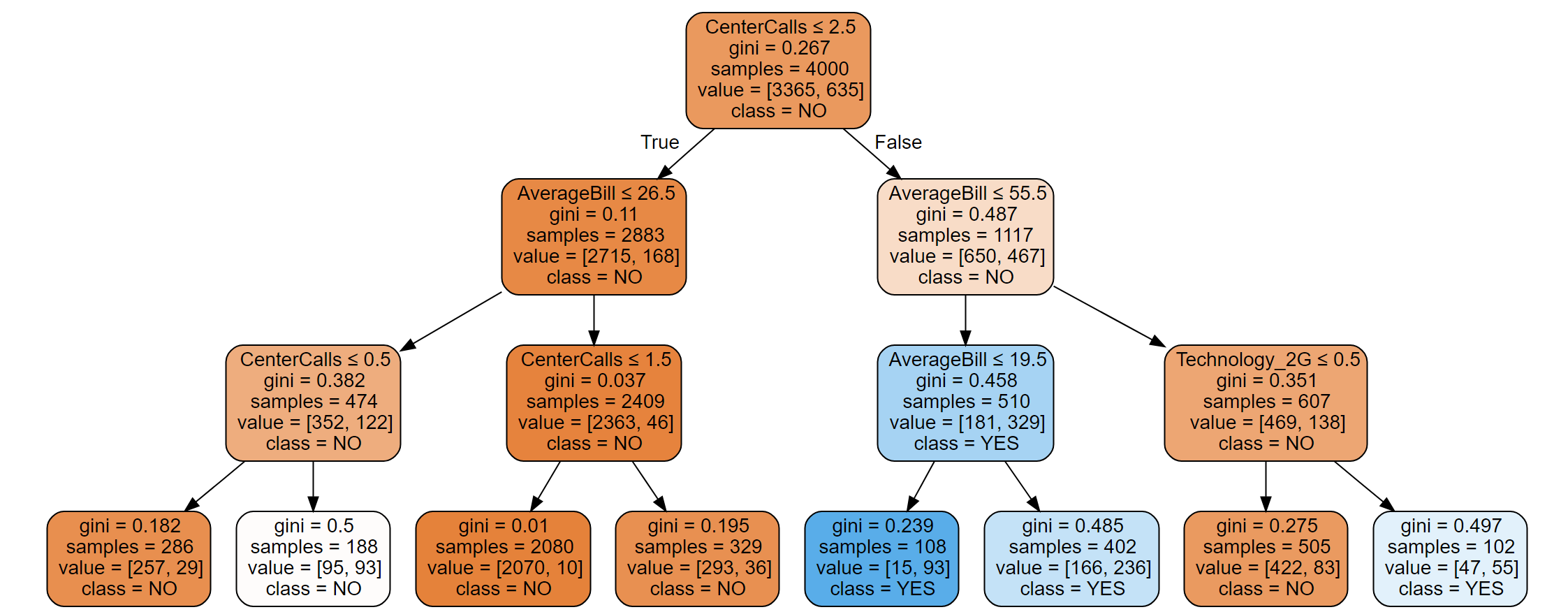
- 첫 번째 질문은 문의전화, 두 번째는 평균 요금
- samples: 4000 전체 데이터 수
- values: [3365, 635] -> y값을 기준으로 NO가 3365, YES가 635 (클래스의 범주)
- 주황색 : NO class, 파란색 - YES class (불순도가 낮을수록 색이 진함)
미지의 고객, 실제로 이탈할까?
- 생성된 의사결정나무를 이용한 분류
df_predict = pd.read_excel('telecom_new.xlsx')
df_predict = pd.get_dummies(df_predict, columns = ['Technology'])
tree_prediction = tree_model.predict(df_predict)
tree_prediction
# 출력 결과
# array(['NO', 'NO', 'YES', 'NO', 'NO', 'NO', 'YES'], dtype=object)predict를 활용하여 결과 확인 가능
회귀도 한다던데, 대체 어떻게?

y가 수치 변수 일 때 값을 예측하는 방법?
- 원리는 동일: CASE |, ||, |||로 나눔
- 각 CASE에 대하여 두 집단으로 나누어서 각 집단의 분산과 표준편차를 계산
- 각 CASE에 대한 가중표준편차를 구함
- 도달한 leaf에 존재하는 모든 y값의 평균을 구해서 예측
3. 분류를 평가하는 여러 가지 방법
분류만 되면 그만? 분류 평가하기

- Accuracy(정확도): 전체 데이터 대비, 정확히 예측한 데이터 비율
- Error Rate = 1 - Accuracy
- Recall: 실제 Positive 데이터 중, 맞게 예측한 비율 (=27/29)
- Precision: 예측 Positive 데이터 중, 맞게 예측한 비율 (=9/10)
- Sensitivity: 실제 Positive 데이터 중, 맞게 예측한 비율 (=27/29)
- Specificity: 실제 Negative 데이터 중 맞게 예측한 비율 (=8/11)