*Colab 이용
| OUTLOOK | TEMPERATURE | HUMIDITY | WINDY | PLAY GOLF |
| Rainy | Hot | High | False | No |
| Rainy | Hot | High | True | No |
| Overcast | Hot | High | False | Yes |
| Sunny | Mild | High | False | Yes |
| Sunny | Cool | Normal | False | Yes |
OUTLOOK object
TEMPERATURE object
HUMIDITY object
WINDY bool
PLAY GOLF object
dtype: object
OUTLOOK category
TEMPERATURE category
HUMIDITY category
WINDY category
PLAY GOLF category
dtype: object
1. ZeroR
ZeroR은 가장 간단한 분류 방법이며, 다른 모든 feature들을 무시하고 label에만 의존합니다.
ZeroR 분류기는 단순히 데이터의 class를 다수 카테고리로 예측합니다.
ZeroR에는 예측 능력이 없지만, 이것은 표준 성능을 가늠하여 다른 분류 방법 성능의 기준점이 됩니다.
0 No
1 No
2 Yes
3 Yes
4 Yes
5 No
6 Yes
7 No
8 Yes
9 Yes
10 Yes
11 Yes
12 Yes
13 No
Name: PLAY GOLF, dtype: category
Categories (2, object): ['No', 'Yes']
Yes 9
No 5
Name: PLAY GOLF, dtype: int64
0.6428571428571429
위의 데이터셋에서 "Play Golf = Yes"로 예측하는 ZeroR모델의 정확도는 0.64가 됩니다.
OneR
OneR은 One Rule의 약자이며, 간단하고 정확한 분류 알고리즘입니다.
OneR은 데이터의 각 feature 마다 하나의 룰 셋(Rule Set)을 생성합니다. 그리고 생성된 룰 셋 중에서, 전체데이터에 대해 오차가 가장 작은 룰 셋을 One Rule로 결정합니다.
각 feature당 룰 셋은 frequency table을 이용하여 만들 수 있습니다.
OneR Algorithm
각 feature 마다,
각 feature의 value 마다, 룰을 아래와 같이 만듭니다.
그 feature의 value에 해당되는 instance중에 target class가 몇개인지 셉니다.
가장 갯수가 많은 class를 찾습니다.
그 feature의 value가 해당되면 그 갯수가 많은 class로 예측되도록 룰을 하나 만듭니다.
각 feature의 룰들의 전체 에러를 계산합니다. (반대로 정확도를 계산할 수도 있습니다.)
가장 작은 에러를 보이는 feature을 선택합니다.
아래 그림에서는 outlook과 humidity feature 모두 에러의 갯수가 4이므로 제일 작습니다. 하지만 활동에서는 첫번째 feature인 outlook만 고려할 것입니다.
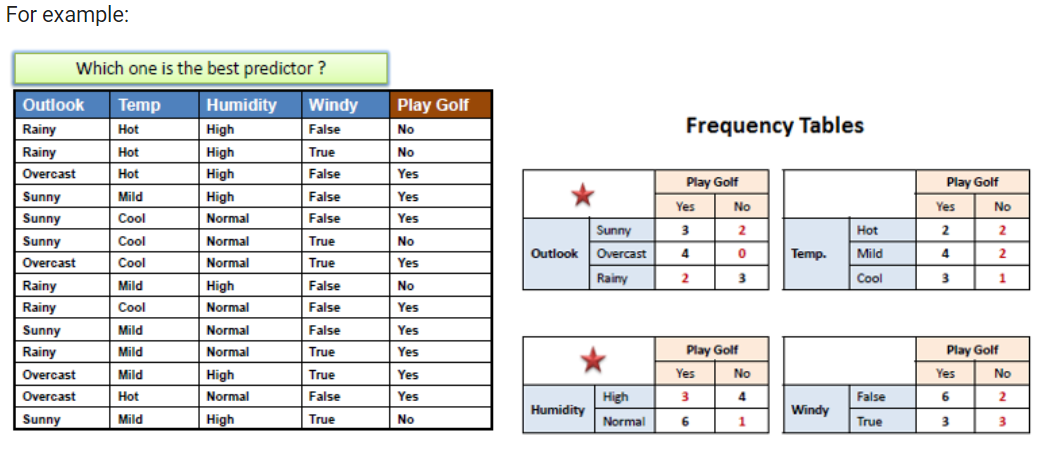
[('No', 3), ('Yes', 2)]
[('Yes', 4)]
[('Yes', 3), ('No', 2)]
error of OUTLOOK: [4]
[('No', 2), ('Yes', 2)]
[('Yes', 4), ('No', 2)]
[('Yes', 3), ('No', 1)]
error of TEMPERATURE: [5]
[('No', 4), ('Yes', 3)]
[('Yes', 6), ('No', 1)]
error of HUMIDITY: [4]
[('Yes', 6), ('No', 2)]
[('No', 3), ('Yes', 3)]
error of WINDY: [5]
OUTLOOK
OUTLOOK : Rainy -> No
OUTLOOK : Overcast -> Yes
OUTLOOK : Sunny -> Yes
Naive Bayes Classifier with scikit-learn
- scikit-learn의 Naive Bayes classifier 다큐멘테이션: https://scikit-learn.org/stable/modules/naive_bayes.html
1.9. Naive Bayes
Naive Bayes methods are a set of supervised learning algorithms based on applying Bayes’ theorem with the “naive” assumption of conditional independence between every pair of features given the val...
scikit-learn.org
| OUTLOOK | TEMPERATURE | HUMIDITY | WINDY | PLAY GOLF |
| Rainy | Hot | High | False | No |
| Rainy | Hot | High | True | No |
| Overcast | Hot | High | False | Yes |
| Sunny | Mild | High | False | Yes |
| Sunny | Cool | Normal | False | Yes |
| OUTLOOK | TEMPERATURE | HUMIDITY | WINDY | PLAY GOLF | |
| count | 14 | 14 | 14 | 14 | 14 |
| unique | 3 | 3 | 2 | 2 | 2 |
| top | Rainy | Mild | High | False | Yes |
| freq | 5 | 6 | 7 | 8 | 9 |
| OUTLOOK | TEMPERATURE | HUMIDITY | WINDY | PLAY GOLF |
| 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 | 1 |
| 2 | 2 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 1 |
OUTLOOK int8
TEMPERATURE int8
HUMIDITY int8
WINDY int8
PLAY GOLF int8
dtype: object
0.9285714285714286
array([[0.125 , 0.5 , 0.375 ],
[0.41666667, 0.25 , 0.33333333]])
array([[0.25 , 0.375 , 0.375 ],
[0.33333333, 0.25 , 0.41666667]])
array([[0.71428571, 0.28571429],
[0.36363636, 0.63636364]])
array([[0.42857143, 0.57142857],
[0.63636364, 0.36363636]])
array([0.35714286, 0.64285714])
[[0.22086561 0.77913439]] [1]
[[0.5695011 0.4304989]] [0]
'대학공부 > 기계학습' 카테고리의 다른 글
| 실습 3차시: Linear/Logistic Regression (0) | 2023.10.13 |
|---|---|
| 실습 2차시: DT (0) | 2023.10.13 |
| Deep NN (0) | 2023.10.11 |
| Feature selection, SVM, 앙상블 (0) | 2023.10.11 |
| Evaluation (0) | 2023.10.11 |