Simple Linear Regression
가장 간단하고 직관적인 기계학습 모델은 데이터의 경향에 맞게 선을 그어주는 것입니다. 이때 데이터에 대해 가장 잘 맞는 선을 찾아가는 과정을 "Linear Regression"이라고 합니다.

Points and Lines
line은 아래의 수식처럼 slope(=m)와 intercept(=b)에 의해 결정됩니다.
Linear Regression에서의 목표는 우리가 가지고 있는 data에서 "가장 좋은"(="최적의") m과 b를 찾는 것입니다.
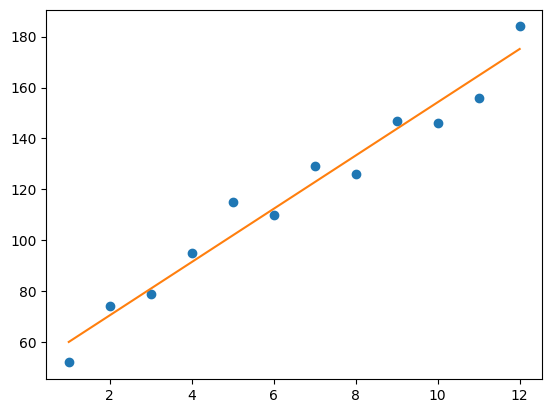
위의 데이터에 대해 최적의 m과 b를 미리 구해 놓았다고 가정하겠습니다. 이때 최적의 m과 b 는 각각 10과 53입니다.
위에서 주어진 최적의 m과 b를 이용하여 months에 대한 예측값 y를 생성하고 이를 실제 관측값인 revenue와 그래프를 그려 비교해봅시다.

Loss
최적의 모델 파라미터(m과 b)를 찾기 위해서는 loss, 혹은 cost을 정의해야합니다.
이때 loss은 모델의 예측값이 실제값과 얼마나 차이가 있는지를 수치로 표현한 것입니다.
아래 그림처럼 해당 실제값에서 예측값까지의 제곱 거리를 loss라고 정의합니다.

결론적으로, 이러한 loss를 기준으로 최적의 모델 파라미터인지 아닌지를 판단합니다. 즉, 주어진 전체 데이터에 대해 loss를 최소로 하는 파라미터(m, b)를 찾는 것이 목표입니다. 이를 식으로 표현하면 아래와 같습니다.
1/N∑(i=1~N)(yi−(mxi+b))^2
3개의 점 (1, 5), (2, 1), (3, 3)가 주어지고, y=x와 y=0.5x+1 두가지 선이 주어졌습니다.
주어진 점들에 대해 예측값을 계산해봅니다.
이 두가지 선 중 위의 식을 토대로 loss를 계산하고, 그 중 loss가 더 작은 선을 골라봅시다.
y = x loss 5.666666666666666
y = 0.5x + 1 loss 4.499999999999999
Gradient Descent for Intercept
Gradient Descent은 최적화 알고리즘 중 하나로서 loss function 혹은 cost function의 global 혹은 local minima을 찾을 때 사용됩니다.
목표는 데이터의 관계를 잘 표현하는 파라미터 m와 b을 찾는 것이며, 이것은 gradient descent을 사용하여 loss function을 최소화함을 통해 얻을 수 있습니다.
최소의 loss를 찾는 것은 마치 아래의 그림처럼 언덕을 내려가다가 바닥에 도착하면 멈추는 것과 비슷합니다. 즉, 파라미터를 loss가 작아지는 방향으로 조정하다가 최소가되면 멈추게됩니다. 이때 loss가 작아지는 방향은 현재의 경사(=gradient)의 반대 방향을 의미합니다.

먼저 intercept(=b)에 대해서 gradient descent를 실행해봅니다. 앞에서 정의한 loss를 b에 대해 미분하여 gradient를 구할 수 있습니다.
2/N∑(i=1~N)−(yi−(mxi+b))
Gradient Descent for Slope
마찬가지로 slope(=m)에 대한 gradient descent를 실행해봅니다. 이번에는 앞에서 정의한 loss를 m에 대해 미분하여 gradient를 구하면 됩니다. 결과는 아래와 같습니다.
2/N∑(i=1~N)−xi(yi−(mxi+b))
Weight Update
b와 m의 gradient를 이용하여 loss가 감소하는 방향으로 b와 m을 update합니다. 그리고 loss가 최소가 되면 weight update가 멈추게 되는데, 그때의 b와 m이 최적의 파라미터가 됩니다.
이때 내려가는 보폭을 조절할 수 있는데 이때 사용되는 것이 "learning rate"입니다. 즉, learning rate가 크면 큰 보폭으로 언덕을 내려가고 learning rate가 작으면 작은 보폭으로 언덕을 내려갑니다.
즉, "learning rate"를 gradient에 곱해주어 보폭을 사용자가 정할 수 있게합니다.
그러나 learning rate는 신중하게 정할 필요가 있습니다.
- learning rate가 너무 작으면 loss의 최솟값에 수렴하는데 시간이 오래 걸립니다.
- learning rate가 너무 크면 최적의 parameter를 얻지 못할 수 있습니다.
learning rate을 사용하여 gradient descent를 수행하여 최적의 파라미터를 찾는 함수를 구현해봅시다.
Example: Sandra’s lemonade stand’s revenue over its first 12 months of being open
이 함수들을 통해 앞에서 생성했던 data에 대해 한 step 후의 update된 parameter를 구해보겠습니다.
b: 2.355
m: 17.78333333333333
최적의 parameter를 찾을 위 과정을 반복해봅니다.
위에서 찾은 최적의 파라미터로 linear regression 모델을 만들어 시각화해봅니다.
49.60215351339813 10.463427732364998
Scikit-Learn 라이브러리 사용
지금까지 linear regression algorithm을 직접 구현했습니다. scikit-learn library를 이용하여 보다 간단하게 linear regression을 사용할 수 있습니다. 다큐멘테이션
scikit-learn에 있는 linear_model 모듈을 통해 linear regression을 실습해보겠습니다.
(단, 위에서 언급했던 learning_rate와 num_iterations은 scikit-learn의 기본값을 사용합니다.)
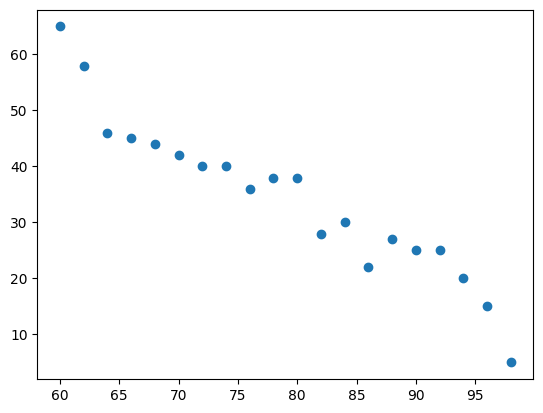
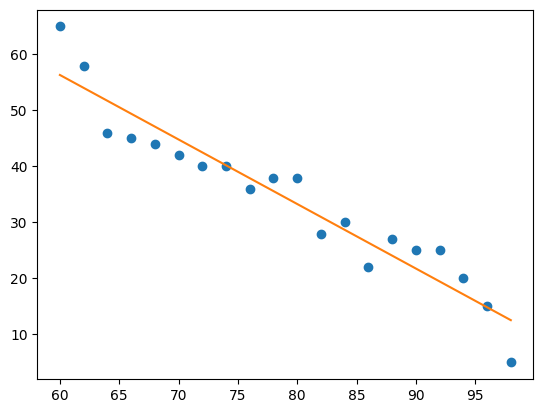
아래의 temperature/sales 데이터를 scikit-learn을 이용하여 fitting 해보겠습니다.
계수(Coefficients)
fitting된 모델에서 계수(coefficients)를 출력해봅니다.
array([-1.15225564])
125.47819548872182
모델 평가
R-Squared (Coefficient of Determination)은 0과 1사이의 값으로 linear regression 모델이 데이터에 얼마나 잘 학습되었는지 나타냅니다. R-Squared가 1에 가까울 수록 모델은 종속 변수(dependent variable)를 잘 예측할 수 있습니다.
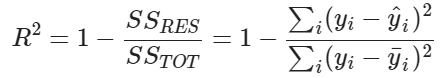
R-squared: 0.9114088011031334
Logistic Regression
Logistic Regression은 데이터가 어떠한 특정 카테고리에 속할지를 0과 1사이의 연속적인 확률로 예측하는 회귀 알고리즘 중 하나입니다. 그런 다음, 확률에 기반하여 특정 데이터가 어떤 카테고리에 속할지를 결정하게 되고, 궁극적으로 classification문제를 풀게 됩니다.
[Linear Regression Approach]
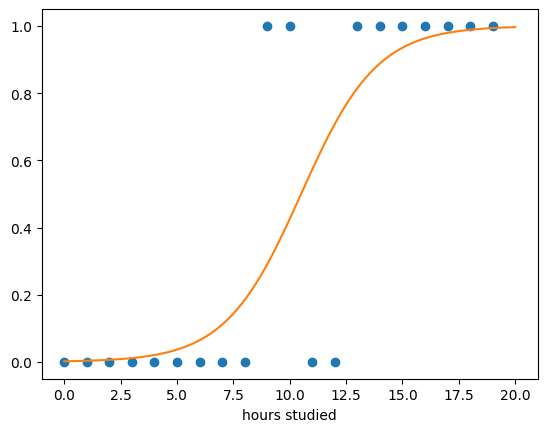
대학교 강의에서 학생들이 기말 시험을 통과할 수 있을지를 예측해보려고 합니다. 각 학생들이 시험을 통과할 확률을 예측함으로써 통과 여부를 예측할 수 있습니다. 여기서 Linear Regression을 활용하면 어떨까요? 한번 해봅시다.
우선 기말 시험 데이터를 확인 해보겠습니다.
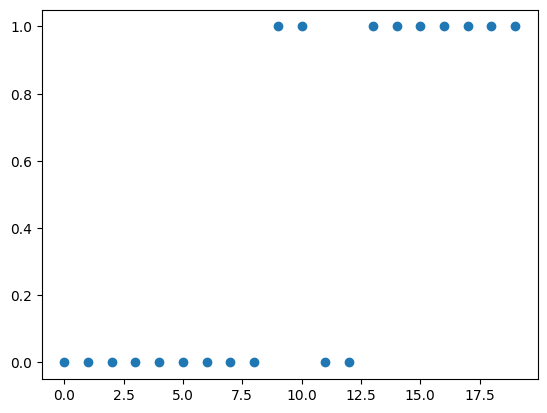
각 학생들이 공부한 시간을 num_hours_studied이라 하고 해당 학생이 중간 시험을 통과한 여부를 y (y 는 통과한 경우 1, 그렇지 않은 경우 0) 라고 한다면 linear regression을 통해 다음과 같이 직선을 그릴 수 있습니다.
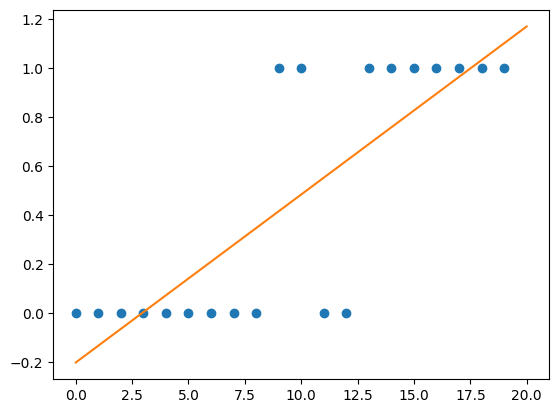
Logistic regression의 예측값은 0과 1사이이므로 위와 같은 linear regression의 한계를 극복할 수 있습니다.
Logistic regression은 다음과 같은 과정으로 수행됩니다.
- 모든 coefficients와 intercept(bias)를 0으로 초기화합니다.
- 각각의 feature를 이에 상응하는 coefficient와 곱한 값과 intercept(bias)를 모두 더해 log-odds를 계산합니다.
- 계산한 log-odds 값을 sigmoid 함수에 전달하여 0 과 1 사이의 확률값을 구합니다.
- 계산한 확률값과 실제 label을 비교하여 loss를 계산하고, gradient descent로 최적의 파라미터를 찾습니다.
- 최적의 파라미터를 찾았다면 classification threshold 값을 조절하여 positive class와 negative class를 어떻게 나눌지를 설정합니다.
[ Log-Odds ]
Linear regression에서는 각 feature에 상응하는 weight의 곱과 intercept(bias)를 더해 예측을 하였습니다.
Logistic regression에서도 마찬가지지만 log-odds를 계산합니다.
log-odds는 특정 데이터가 positive class에 속할 확률을 표현합니다. 통계에서 특정 사건의 odds(승산)을 계산하는 공식은 다음과 같습니다.
P(A): 특정 사건이 발생할 확률
1−P(A): 특정 사건이 발생하지 않는 확률
Odds = P(A) / (1-P(A))
Odds는 특정 사건이 일어나는 횟수가 특정 사건이 일어나지 않는 횟수보다 얼마나 더 많은지를 의미합니다. 만약 특정 학생이 시험에서 pass할 확률이 0.7이라면, pass하지 못 할 확률은 1 - 0.7 = 0.3 이고, 이 경우 odds를 다음과 같이 계산할 수 있습니다.
Odds of passing = 0.7 / 0.3 = 2.33
Odds는 0과 양의 무한대의 값을 범위로 갖습니다.
그렇기 때문에 제약이 있고, 또, 확률값과 odds 값은 비대칭성을 띕니다.
이러한 한계를 극복하기 위하여 odd에 로그를 취하는것을 log-odds라 하고, 음의 무한대부터 양의 무한대까지의 범위를 갖습니다.
Log odds of passing = log(2.33) = 0.847
Logistic regression 모델에서 아래와 같이 z 값으로 나타내지는 log-odds 값을 계산할 수 있습니다.
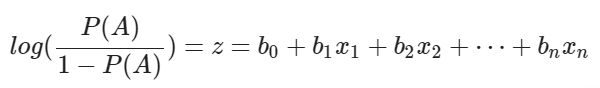
이로써 특정 데이터의 feature values를 해당 데이터가 positive class에 속할 가능성으로 매핑할 수 있습니다.
이 때 이러한 곱의 합을 dot product(내적) 이라고 합니다. 내적은 numpy의 np.dot() 메서드를 활용하여 쉽게 계산할 수 있습니다.
기말 시험 데이터에서 최적의 coefficient와 intercept가 각각 0.03, −0.3이라고 가정했을 때의 log-odds를 계산 해봅시다.
array([[-0.3 ], [-0.27], [-0.24], [-0.21], [-0.18], [-0.15], [-0.12], [-0.09], [-0.06], [-0.03], [ 0. ], [ 0.03], [ 0.06], [ 0.09], [ 0.12], [ 0.15], [ 0.18], [ 0.21], [ 0.24], [ 0.27]])
[ Sigmoid Function ]
Sigmoid Function은 log-odds인 z 값을 취해서 아래와 같이 0 과 1 사이의 값을 반환합니다.
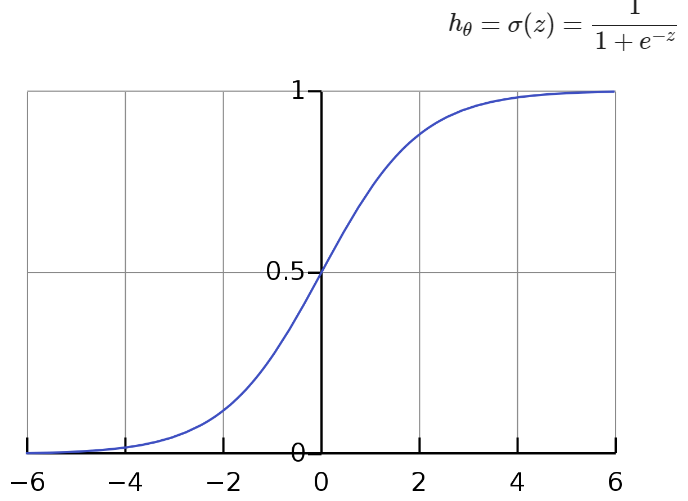
Logistic Regression이 특정 데이터가 positive class에 속할 확률을 계산합니다.
[[0.42555748] [0.4329071 ] [0.44028635] [0.44769209]
[0.45512111] [0.46257015] [0.47003595] [0.47751518]
[0.4850045 ] [0.49250056] [0.5 ] [0.50749944]
[0.5149955 ] [0.52248482] [0.52996405] [0.53742985]
[0.54487889] [0.55230791] [0.55971365] [0.5670929 ]]
[ Log-Loss ]
이제 최적의 coefficients와 intercept를 구해보겠습니다. 이를 구하기 위해서는 주어진 모델의 예측이 실제 데이터에 얼마나 가까운지 측정하는 기준이 필요합니다. 이를 loss function 혹은 cost function이라고 합니다.
모델이 데이터에 ‘fit’ 하단걸 측정하기 위해선 먼저 각 데이터에 대한 loss를 계산한뒤 loss의 평균을 내야합니다. Logistic regression에서의 loss function은 Log Loss라고 불리며, 공식은 다음과 같습니다.
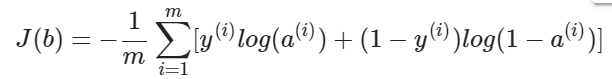
- m 은 전체 데이터의 개수입니다.
- y(i)는 i 번째 데이터의 class 입니다.
- a(i)는 i 번째 데이터의 log-odds 값에 sigmoid 를 취한 값입니다. 즉 i 번째 데이터가 positive class에 속할 확률을 나타냅니다.
만약 i 번째 데이터의 class가 y=1 이라면 해당 데이터에 대한 loss는 다음과 같습니다.
loss를 최소화 시키려면 a(i) 값이 커야 합니다. 즉, 예측된 확률 값이 원래 class인 1 에 가까울수록 loss는 줄어들게 됩니다.
반대로 i 번째 데이터의 class가 y=0 인 경우는 다음과 같습니다.
loss를 최소화 시키려면 a(i)값이 작아야 합니다. 즉, 예측된 확률 값이 원래 class이 0에 가까울수록 loss는 줄어들게 됩니다.
아래의 그래프는 class가 y=1, y=0 일 때 a값에 따라 loss가 어떻게 변화하는지를 나타냅니다.
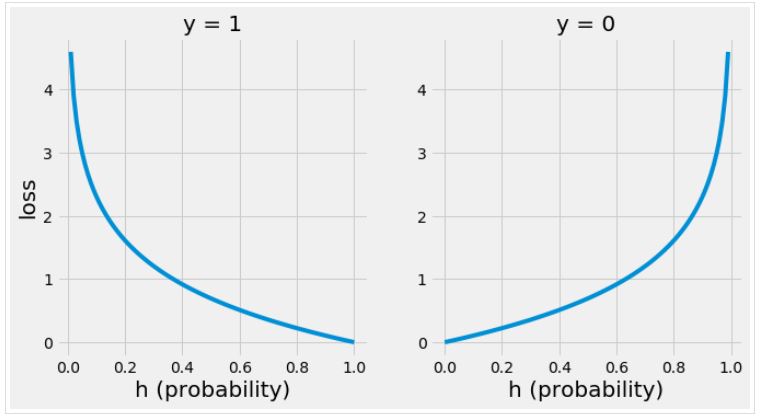
그래프를 보면 올바르게 예측할수록 loss가 줄어드는 것을 볼 수 있습니다. 반대로 잘 못 예측하게 되면 loss가 크게 증가하는데, 이는 모델이 잘못 예측할 때 패널티를 강하게 줌으로써 올바른 예측을 할 수 있도록 유도할 수 있습니다.
0.6279073897953891
[ Classification Thresholding ]
Logistic Regression은 예측된 확률 값이 임계값을 넘느냐 못 넘느냐에 따라서 class를 분류합니다. 이 임계값을 classification threshold 라고 합니다.
Classification threshold의 기본값은 0.5 입니다. 만약 특정 데이터의 예측된 확률 값이 0.5 보다 크거나 같다면 해당 데이터는 positive class로 분류됩니다. 반대로 예측된 확률 값이 0.5 보다 낮다면 negative class로 분류됩니다.
만약 더욱 엄격하게하고자 한다면 threshold를 0.6이나 0.7로 조정할 수 있습니다. 즉, 모델이 positive class를 더 적게 예측할 수 있도록 하는 것입니다.
이에 대해 예측된 확률값이 임계값을 넘으면 1, 그렇지 않으면 0 을 반환하는 함수를 구현해보겠습니다.
[[0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1]]
이번에는 더욱 엄격하게 threshold를 0.55로 설정하여 위의 결과와 비교해봅니다.
[[0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [0] [1] [1] [1]]
[ Scikit-Learn ]
scikit-learn에서 제공하는 메서드를 활용하여 Logistic Regression을 구현해봅니다.
[[0.59365161]] [-6.23665281]
'대학공부 > 기계학습' 카테고리의 다른 글
| 실습 5차시: 성능 평가, cross validation (0) | 2023.10.20 |
|---|---|
| 실습 4차시: 퍼셉트론, MLP (0) | 2023.10.20 |
| 실습 2차시: DT (0) | 2023.10.13 |
| 실습 1차시: ZeroR, OneR, Naive Bayes Classifier (0) | 2023.10.11 |
| Deep NN (0) | 2023.10.11 |



