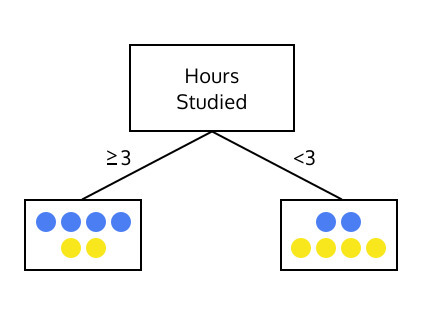
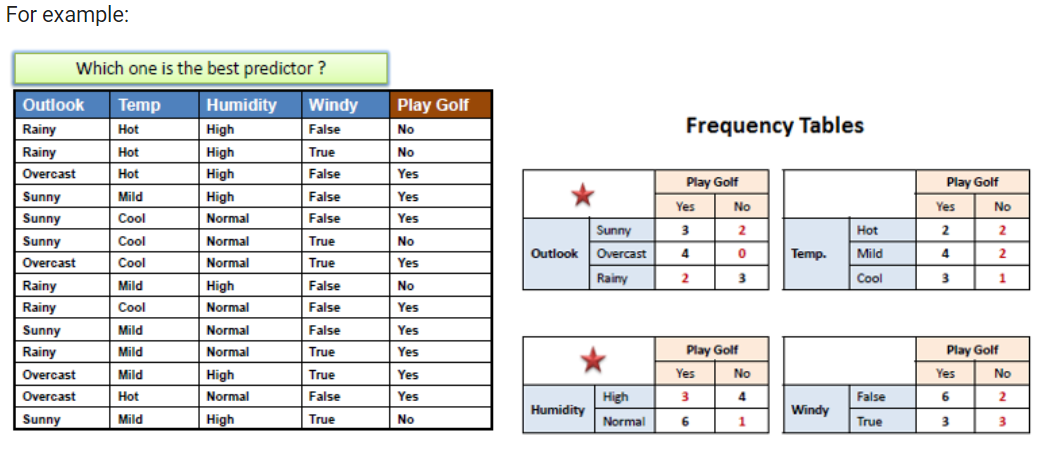
1. K-Nearest Neighbor Classifier (KNN) 1-1. 데이터 포인트 간의 거리 - 2D 이번 실습에서는 KNN 모델로 영화 평가 분류기를 구현해볼 것입니다. 먼저 데이터 포인트들 간의 거리 개념부터 알아봅니다. 두 점이 서로 가깝거나 멀리 떨어져 있는 정도를 측정하기 위해 거리 공식을 사용할 것입니다. 이 예제의 경우 데이터의 차원은 다음과 같습니다. 영화의 러닝타임 영화 개봉 연도 스타워즈와 인디아나 존스를 예로 들겠습니다. 스타워즈는 125분이며 1977년에 개봉했습니다. 인디아나 존스는 115분이며 1981년에 개봉했습니다. 이 두 영화를 의미하는 두 데이터 포인트들의 거리는 아래와 같이 계산됩니다. Practice 1 1. movie1과 movie2라는 두 리스트을 매개 ..