자연어 분석 단계
- 자연언어 문장
- 형태소 분석
- 구문 분석 - 문장의 구조 이해
- 의미 분석 - 중의성 확인
- 화용 분석
어휘 분석
형태소 분석이란?
- 어휘 분석: 단어의 구조를 식별하고 분석을 통한 어휘의 의미와 품사에 관한 단어 수준의 연구
- 형태소 분석: 더 이상 분해될 수 없는 최소한의 의미 단위인 형태소를 자연어의 제약 조건과 문법 규칙에 맞춰 분석하는 것
- 필요성: 한국어는 조사에 따라 의미가 변함
- ex. 날다 -> 나는 (Me or Fly?) // 일종의 중의성
- 고유명사, 사전에 등록되지 않은 단어 처리에 도움이 됨
- 필요성: 한국어는 조사에 따라 의미가 변함
형태소 분석 절차
- 단어에서 최소 의미를 포함하는 형태소 후보로 분리
- 형태소 분석의 처리 대상: 어절(하나 이상의 형태소가 연결된 것)
- 형태소열
- 예시) 한국어(Korean)는 = 한국어 + ( + Korean + ) + 는
- 한국어에서 형태소가 연결될 때 형태소의 변형이 일어나므로 형태소 원형 복원이 필요
- 형태론적 변형이 일어난 형태소의 원형 복원 및 형태소품사쌍 생성
- 형태소품사쌍: 형태소와 그 형태소의 품사를 쌍으로 나타낸 것
- 영어에서 최소 단위의 의미를 갖는 기본 단위는 단어
- 어간 추출(Stemming), 표제어 추출(Lemmatization)을 통해 쉽게 형태소 파악 가능
- 일반적으로 영어의 형태소는 접사
- ex. unsure에서 un이 접두사, careful에서 ful이 접미사
- 한국어 형태소 분석기의 오픈 라이브러리가 여러 존재
- KoNLPy - KUKoLex(고려대), 한나눔(Hannanum), 코모란(Komoran), 미캡(mecab), 꼬꼬마(Kkma)
- Khaiii(Kakao Hangul Analyzer |||) - 딥러닝 이용한 형태소 분석기
- 단어와 사전들 사이의 결함 조건에 따라 옳은 분석 후보를 선택
- 형태소품사쌍열 후보군 중 선택
- ex. "나_대명사 + 는_조사", "나_일반명사 + 는_조사", "나_동사 + 는_어미" 등등...
- 확률로 계산
- 형태소품사쌍열 후보군 중 선택

품사 태깅이란?
- 품사: 단어의 기능, 형태, 의미에 따라 나눈 것
- 태깅: 같은 단어에 의해 의미가 다를 경우(중의성)을 해결하기 위해 부가적인 언어의 정보를 부착
품사 태깅 접근법
1. 규칙 기반의 접근법
- 언어 정보에서 생성되는 규칙 형태로 표현을 적용하여 태깅 수행
- 장점: 어절에 대해 높은 정확도를 나타내기 때문에 통계 기반 접근법으로 다루지 못하는 부분에 대한 교정이 가능, 사람이 만들기 때문에 성능이 좋음.
- 단점: 반드시 전문가가 필요, 비용이 많이 듦, 모든 규칙을 만들 수 없으므로 규칙이 존재하지 않으면 판단이 불가능
- 긍정 정보: 문장에서 선호되는 어휘 태그에 대한 언어 지식
- 부정 정보: 특정 문장에서 배제되는 어휘 태그에 대한 언어 지식
- 수정 정보: 오류 교정. 잘못된 정보 입력 시 수정될 정보에 대한 지식
2. 통계 기반의 접근법
- 장점: 데이터만 있으면 모델이 패턴을 알아서 학습해서 최적의 경로를 출력. 새로운 문장에 대해서 판단 가능.
- 단점: 그만큼 학습할 만한 많은 데이터가 필요.
- Hidden Markov Model(HMM)
- 어휘 확률만 이용하는 방법인 은닉 마코프 모델(HMM)이 가장 성능이 좋은 접근 방법
- 주어진 문장에서 형태소의 품사 태그 정보를 숨긴 채로 확률 정보를 이용해서 가장 가능성이 높은 경로를 찾음
3. 딥러닝 기반의 접근법
- 데이터로부터 특징을 자동으로 학습
- 폭넓은 문맥 정보를 다룰 수 있음
- 모델에 적합한 출력을 다루기가 간단
장점: 가장 성능이 좋음. 새로운 문장에 대한 계산이 가능.
단점: 통계 기반보다 훨씬 더 많은 데이터가 필요, 블랙박스 모델(연산 과정 중 일부를 수정 불가능, 결과 해석 불가능).
구문 분석
구문 분석 개요
- 구분 분석: 자연어 문장에서 구성 요소들의 문법적 구조를 분석하는 기술
- 자연어처리 기술에서 문장 의미의 분석을 돕는 세부 기술로 활용 가능
- 목표: 자연어 문장의 문법적 구조를 '구문 문법'에 따라 자동으로 분석하는 것
- 구문 문법: 언어학에서 문법적 구성 요소들로부터 문장을 생성하고 또 반대로 문장의 구성 요소들로 분석하는 기법
- 구구조 문법
- 의존 문법
구문 중의성
- 구문 중의성: 자연어 문장의 구문 구조가 다양한 방식으로 분석될 수 있는 특징
- 해소를 위해서는 의미, 문맥 등 추가적이 정보가 필요
- 구문 분석을 통해 중의성을 해결할 수 있음
구구조 구문 분석의 접근법
- 구구조 구문 분석: 구구조 문법에 기반한 구문 분석 기술
- 단어들과 단어들로 구성한 절의 계층적 관계에 따라 문자 구조 분석
- 문장 이해 및 중의성 해결을 위해 가장 적합한 트리를 찾는 것이 목적
1. 규칙 기반
인간이 가지고 있는 언어학적 지식을 컴퓨터가 이해할 수 있는 형태의 문법 규칙으로 미리 정의한 뒤 이를 자연어 문장에 정의함으로써 구문 분석 수행
- 구구조 문법: 자연어 문장을 하위 '구성소'들로 나눔으로써 문장 구조를 나타내는 문법
- 구성소: 한 개의 단위같이 기능하는 일련의 단위들
- 구구조 문법의 구조: A -> BC
- 구성소 A가 하위 구성소 B와 C로 분석될 수 있음

결정적 문맥 자유 문법을 적용한 형식 언어 분석 알고리즘으로 수행 가능
- 대표 알고리즘: CYK 알고리즘(Cocke-Younger-Kasami Algorithm)
2. 통계 기반
통계적으로 확률적 구구조 문법을 계산하여 이를 바탕으로 구문 분석을 수행하는 접근 방법
- 문법 규칙은 '확률적 구구조 문법'으로 표현
- 각 규칙에 대한 조건부 확률이 정의됨
- 확률적 구구조 문법의 생성 규칙: A -> BC[p]
- p: 구성소 A가 하위 구성소 B와 C로 분석될 조건부 확률
- 분석 결과의 전체 확률이 가장 높은 것을 구문 분석 결과로 제시


3. 딥러닝 기반
인간이 구축한 구구조 구문 분석 데이터셋으로부터 딥러닝 모델을 학습하여 구문 분석을 수행하는 접근 방법
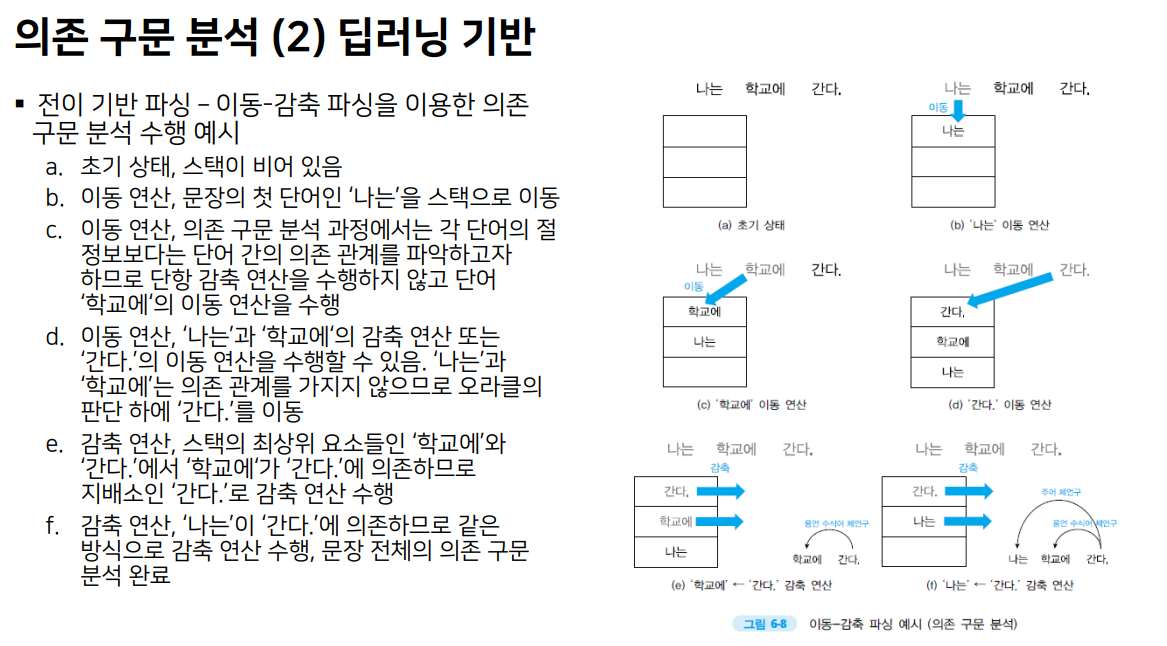
- 대표적인 방법: 전이 기반 파싱
- 자연어 문장을 한 단어씩 읽으며 현재 단계에서 수행할 액션을 선택하는 방식으로 문장 전체의 구구조 구문 분석을 수행하는 방법
- 대표적인 전이 기반 파싱 방법: 이동-감축 파싱
- 각 전이 단계에서 선택할 수 있는 액션: 이동, 단항 감축, 이항 감축
- 이동 연산: 자연어 문장에 포함된 단어를 순차적으로 스택에 이동시키는 연산
- 감축 연산: 스택에 저장된 하나 또는 두 개의 구성소를 꺼내 상위 구성소를 감축한 뒤 다시 스택에 이동시키는 연산
- 오라클(Oracle): 각 전이 단계에서 어떤 액션을 선택할 것인지를 결정
- 각 전이 단계에서 선택할 수 있는 액션: 이동, 단항 감축, 이항 감축
- 장점: 입력된 자연어 문장에 포함된 단어 수에 선형적인 전이 액션으로 구문 분석 가능
- 단점: 각 전이 액션 선택시 문장 전체의 문법적 구조를 고려하는 것이 어려움. 이에 따라 문장 내 거리가 먼 단어들 간 의존 관계 분석이 어려움. 오류 전파에 취약.


의존 구문 분석의 접근법
- 의존 구문 분석: 자연어 문장에서 단어 간의 의존 관계를 분석함으로써 문장 전체의 문법적 구조를 분석하는 기술
- 단어 간 의존 관계와 그 유형 분석을 통해 문장의 문법적 구조를 적합하게 표현하는 의존 분석 트리를 구축하는 과제
(1) 규칙 기반
- 의존 문법의 형태로 문법 규칙을 저장한 뒤 이를 적용하여 의존 구문 분석 수행
- 지배소(Head): 의존 관계 표현에서 절의 중심이 되는 단어
- 의존소(Modifier): 절 내에서 지배소에 의존하는 단어
- CG(Constraint Grammer): 규칙 기반 의존 구문 분석을 위한 문맥 의존 규칙을 정의하는 문법
(2) 통계 기반
- 문맥 의존 규칙의 조건부 확률을 통계적으로 계산하여 의존 구문 분석에 적용함으로써 수행
(3) 딥러닝 기반
- 전이 기반 파싱: 자연어 문장에 포함된 단어를 하나씩 의존 분석 트리에 포함시킴으로써 의존 구문 분석을 수행하는 방식
- 그래프 기반 파싱: 자연어 문장에 포함된 단어 간의 가능한 모든 의존 관계에 대한 점수를 계산한 뒤, 문장 전체에서 가장 높은 점수를 갖는 의존 분석 트리를 선택하는 방법
비슷하지만 더 간단: 이동과 감축만 있음
구구조와 똑같이 문장이 길어지면 앞을 잘 고려하지 못함
규칙 기반 구문 분석 방법의 장단점
- 장점
- 미리 정의된 문법 규칙을 적용할 수 있는 문장에 대해서는 정확한 의존 분석 수행 가능
- 단점
- 적용할 문법 규칙을 미리 정의하기 위한 시간과 비용 문제 발생
- 언어학적 지식을 직접 구구조 문법 형태로 정의해야 하므로, 언어학에 대한 전문성을 가진 노동력 요구
- 방대한 문법 규칙을 정의하는 데 많은 시간과 비용 소요
- 수동으로 정의되지 않은 문법 규칙에 대해서는 구문 분석 수행 불가
- 자연어 문장의 중의성 처리 시 문제 발생
통계 기반 구문 분석 방법의 장단점
- 장점
- 구문 중의성을 갖는 문장에서도 가장 타당한 구문 분석 결과 선택 가능
- 단점
- 구문 분석 과정에서 요구되는 언어적 정보를 충분히 활용하지 못함
- 장거리 의존 관계를 고려하기 어려움
딥러닝 기반 구문 분석 방법의 장단점
- 장점
- 앞에서 활용하기 어려운 문장 전체 구조 정보, 어휘의 하위 범주화 정보 등을 특징 벡터의 계산에 반영함으로써 구문 분석에 활용 가능
- 단점
- 결과의 근거가 해석 불가능
더 알아보기
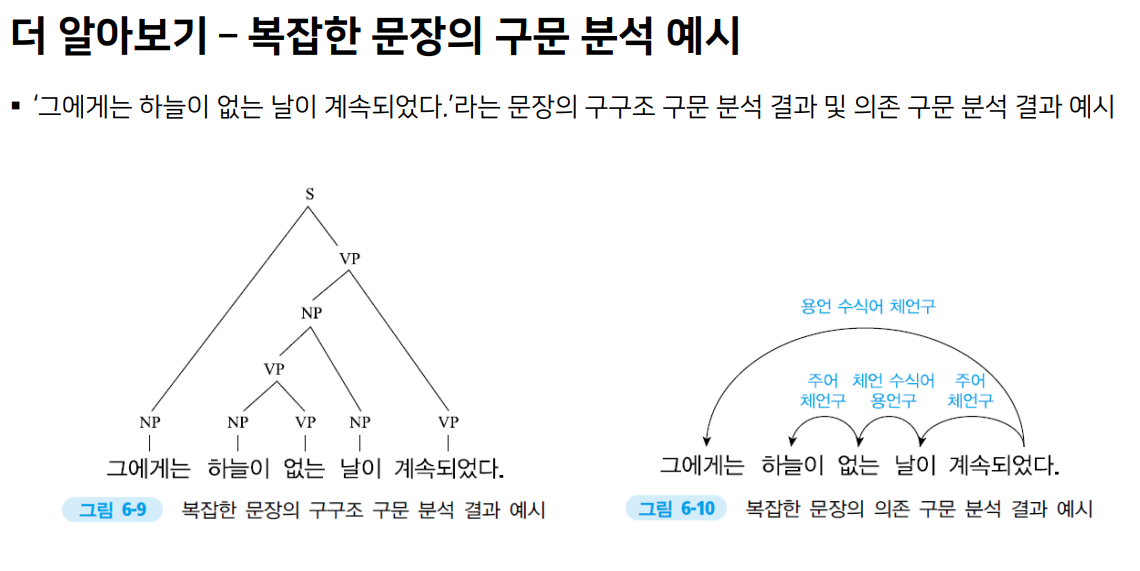
구와 의존 관계 유형 예시
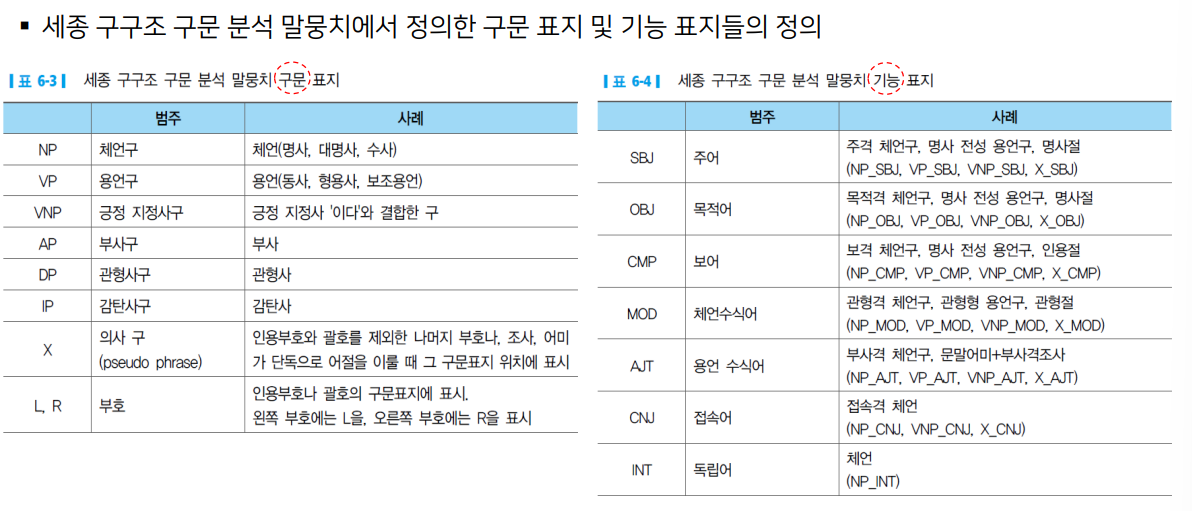
구구조 구문 분석 - 구의 유형으로 정의
- 구의 유형: 구문 표지 + 기능 표지
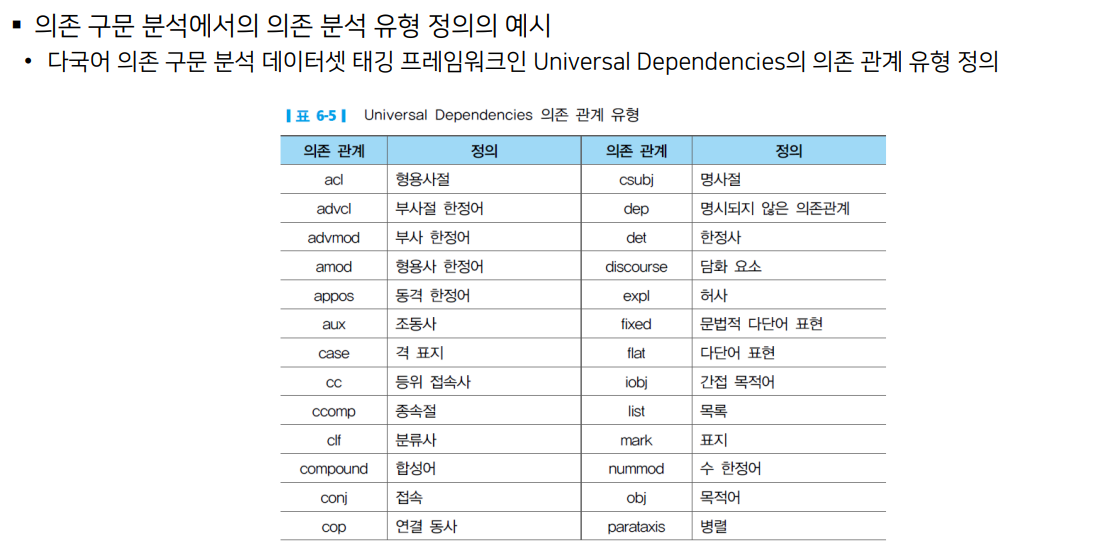
의존 구문 분석 - 의존 관계 유형으로 정의
의미분석
문장 분석 이후 의미 분석을 통해 중의성을 해결
- 중의성: 둘 이상의 의미를 가지는 표현
- 적절한 문맥 정보와 함께 표현되어야 함
- 어휘적 중의성: 다의어에 의한 중의성
- 예) 손 좀 보다
- 동음어에 의한 중의성
- 예) 밤이 좋다
- 구조적 중의성: 수식어에 의한 중의성
- 예) 부유한 철수와 영희가 명품 매장을 갔다
- 어휘적 중의성: 다의어에 의한 중의성
단어 의미 중의성 해소 기법
중의성을 가지는 어휘를 정의된 의미와 매칭하여 문맥에 맞게 어휘적 중의성을 해결
지식 기반 방법
사전에 정의된 어휘 지식을 활용하여 예측
- 사전 정의 기반 방법 - Lesk 알고리즘
- 중의성 단어의 주변 문맥에 나타난 단어의 사전 뜻풀이에 쓰인 단어들 사이에 중복되는 단어가 가장 많은 의미를 중의성 단어의 의미로 선택
- 한계점
- 단어 간의 정확한 일치가 기반
- 사전 정의에 굉장히 의존적
- https://github.com/nlpai-lab/nlp-bible-code/tree/master/07%EC%9E%A5_%EC%9D%98%EB%AF%B8%EB%B6%84%EC%84%9D
- 그래프 기반 방법 - 단순 그래프 기반 방법
- 중의성 단어인 drink와 milk의 synset들을 WordNet에서 추출
- DFS, BFS 알고리즘을 활용
- 의미 간 연결성 측정을 통해 가장 많이 연결된 의미를 선택
지도학습 기반 방법
기계학습 분류기 모델은 사용자가 정의한 규칙에 맞춰 선택된 자질에 따라 성능을 높여옴
학습한 특정 중의성 단어에 대해서만 해결 가능
- Naive Bayes Classifiers
- 각 의미에 대해서 더 높은 확률을 가지는 의미를 선택
- k-Nearest Neighbor Classifiers
- 벡터 공간에 표현된 자질들을 정해진 k값에 따라서 가장 많이 묶이는 자질들의 의미클래스로 선택
- Support Vector Machine
- 벡터 공간에 표현된 자질로부터 의미 클래스를 분류하기 위해 의미 클래스 간에 가장 넓은 거리를 사용하는 방향으로 선을 그어 의미를 분류
텍스트 전처리
비정형 데이터 내의 오류
- 비정형 데이터: 일정한 규격이나 형태를 지닌 숫자 데이터와 달리 그림이나 영상, 문서처럼 형태와 구조가 다른 구조화 되지 않은 데이터
- ex. SNS 데이터
- 전처리 과정: 비정형 데이터의 오류를 수정하는 과정
텍스트 문서의 변환
- 목적으로 하는 파일로부터 텍스트를 추출하는 것이 전처리의 첫 번째 단계
- 목표 언어의 어휘만 남아있어야 함: 특수문자 및 불필요한 타 언어 문제의 제거
- 다양한 방법
- 특수문자 제거
- 특수 커맨드 또는 코딩을 규칙적으로 제거
- PDF의 경우 텍스트를 문장단위로만 끊게 함으로써 줄 바꿈과 같은 요소를 무시
- 문장 경계 인식
띄어쓰기 교정
- 띄어쓰기: 한국어는 크게 의미분절, 가독성, 의미혼용 방지의 용도
- 띄어쓰기로 인해 의미 변환이 있으며 이는 성능 저하의 요인 -> 띄어쓰기 교정기를 사용
띄어쓰기 교정 방법
(1) 규칙 기반
주로 어휘 지식, 규칙, 오류 유형 등의 휴리스틱 규칙을 이용
- 장점: 높은 정확도
- 단점
- 해당 규칙은 해당 답변에서만 사용 가능
- 실질적으로 무한한 경우의 수를 고려해 모든 규칙을 사람이 만드는 것이 불가능
- 비교적 분석 과정이 복잡, 어휘 지식 구축관리 비용이 큼
- 시스템 유지 보수가 어려워짐
- 손수 제작해야 하므로 시간적, 인적 비용이 막대하게 증가
- 어절 블록 양방향 알고리즘
- 어절 블록 인식
- 어절 블록 내의 오류 인식
- 어절 인식 오류 교정
- 규칙 적용의 중의성을 띄는 구간이나 오타에는 성능이 저하
(2) 확률 기반
말뭉치로부터 자동 추출된 확률 정보를 기반으로 기계적인 계산 과정을 거쳐 띄어쓰기 오류 교정
- 장점
- 구현 용이
- 어휘 지식 구축관리 및 미등록어에 대해 견고한 분석 가능
- 단점
- 학습 말뭉치의 영향을 크게 받음으로써 정확도 및 오류율이 높음
- 대량의 학습 데이터를 요구 - 한국어의 경우 띄어쓰기가 올바른 학습 말뭉치를 구하기 어려움
철자 및 맞춤법 교정
철자 교정: 정확한 의미 전송 및 정보 교환에 필요
의미혼용 방지 및 정보전달 실패 방지를 위해 반드시 필요
-> 이를 위해 '맞춤법 검사'를 시행
- 텍스트 내 오류 감지 - 형태소 분석기 이용
- 오류의 수정
- 오타로 인해 발생할 수 있는 오류: 삽입, 생략, 대체, 순열(순서가 뒤바뀜)
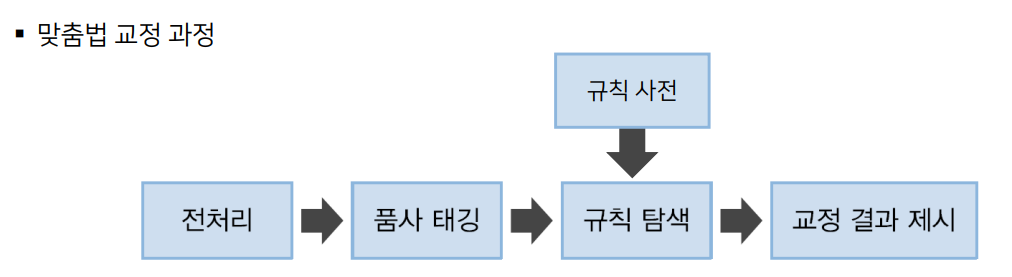
(1) 규칙 기반
- 언어 현상의 규칙성을 추가로 응용하는 방식
- 어절을 형태소들로 분절하는 '형태소 분석기'를 사용한 방식이 존재
(2) 확률 기반
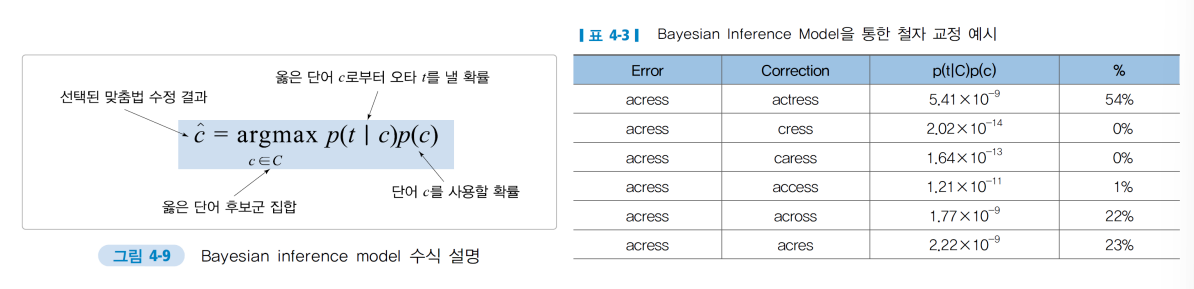
- Bayesian inference model: 올바른교정 결과를 도출하기 위해 주어진 단어로부터 오타가 일어날 확률을 확률적으로 계산하는 방법
- 가장 확률이 높은 교정 후보군을 선택해 대체하도록 철자 교정
'대학공부 > 자연어처리' 카테고리의 다른 글
| 언어 모델(Language Model): 통계적 언어 모델 (0) | 2024.04.12 |
|---|---|
| 자연어처리 task (0) | 2024.03.27 |
| 자연어처리의 기본 (2) | 2024.03.13 |
| 인간 지능을 흉내 내는 인공지능 (0) | 2024.03.13 |