영상: https://www.youtube.com/watch?v=7DwxuWyCNHA&list=PLgXGHBqgT2TvpJ_p9L_yZKPifgdBOzdVH&index=2
예시 상황
- 쇼핑몰 블랙 프라이데이 이벤트 진행으로 50퍼센트 할인
- 많은 유저가 몰릴 것을 대비하여 취약점 진단(약 평소 5배)
- WAS와 DB가 하나인 구조
- 로드밸런서와 WAS 여러 개로 개선
- 결과: DB의 CPU 사용률과 메모리 사용률이 100%, 데이터베이스 크래시 발생
-> 고가용성(High Availability)이 중요
DB Replication
- 데이터베이스 고가용성을 위한 기술
- Mysql 8.0, innoDB 기준
개념
- DB Replication: 한 데이터베이스에서 다른 데이터베이스로 데이터가 동기화되는 것
- Source(원본 데이터 소장) -> Replica(복제된 데이터 소장)
- 필요성
- source에는 쓰기 요청, replica에는 읽기 요청을 보내기
- 트래픽이 많은 상황에서도 부하 분산을 통한 고가용성 확보
- 트래픽 때문이 아니더라도 다양한 상황에서 고가용성 확보
- 예비용 / 데이터 분석용 / 데이터 백업용 / 지리적 분산용 서버
- 복제 시스템 구성 방법
- Single Replilca 구조: source, replica 1개씩
- Multi Replica 구조: source 1개, replica 2개
- 체인 복제 구성
- 듀얼 소스 복제 구성
- 멀티 소스 복제 구성 등
복제 아키텍처
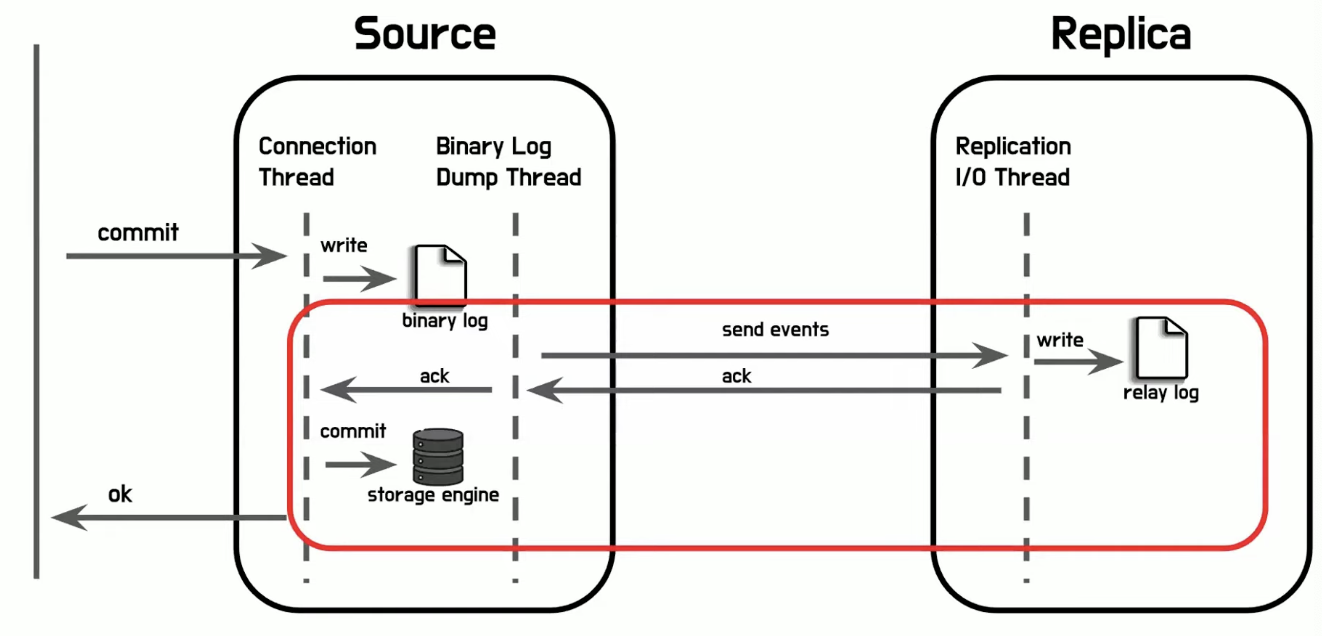
- 복제를 수행하는 시스템 아키텍처와 복제 과정의 흐름
- 바이너리 로그: MySQL 서버에서 발생하는 모든 변경 사항이 기록된 파일
- 수행된 DML, DDL, 메타데이터 변경 등
- 설정에 따라 SQL 또는 변경된 데이터 Row가 저장됨
- 복제 아키텍처
- Binary Log를 이용
- Source의 변경 사항이 바이너리 로그에 기록되면 Replica에 전파됨

- 트랜잭션 처리 스레드가 바이너리 로그에 변경을 기록
- Replica 서버에서 바이너리 로그 요청 시 바이너리 로그 덤프 스레드를 변경 조회 후 바이너리 로그 전송
- 레플리케이션 I/O 스레드가 릴레이 로그에 변경 쓰기
- 레플리케이션 SQL 스레드가 변경을 조회한 후 데이터 파일에 반영
복제 타입
- 복제 타입: 복제 이벤트를 식별하는 방식
- 복제를 위해 레플리카는 소스 데이터베이스에 복제 정보를 요청
- 이때 약속된 타입의 데이터로 요청해야 함
- MySQL에서 제공하는 복제 타입
- 바이너리 로그 파일 위치 기반 복제
- 글로벌 트랜잭션 아이디 기반 복제
바이너리 로그 파일 위치 기반 복제
- 특정 바이너리 로그 파일과 position의 조합 타입으로 복제 정보 요청
- 물리적인 방식
- 문제점
-
- 소스 서버에 장애가 발생하면 레플리카 서버 중 동기화가 되지 않은 서버가 소스 서버로 승격된 경우
- 레플리카가 새로운 소스 서버에 복제 정보를 요청했을 때 해당 정보가 없을 수 있음
- 이유: 특정 복제 이벤트가 다른 데이터베이스에서 동일한 위치에 저장되는 것을 보장하지 않음
- 소스 서버의 장애가 발생하면 복구가 어려움
- 소스 서버에 장애가 발생하면 레플리카 서버 중 동기화가 되지 않은 서버가 소스 서버로 승격된 경우
글로벌 트랜잭션 아이디 기반 복제
- GTID: 복제 시스템 내에 모든 DB가 공유하는 유니크한 트랜잭션 ID
- 소스 서버의 유니크한 ID값과 트랜잭션 ID 값의 조합으로 만들어짐
- 논리적인 방식
- 하나의 이벤트를 동일한 식별자로 알 수 있게 된다
- 소스 서버 장애 상황에서도 유연
복제 동기화 방식
- 복제 이벤트를 얼마나 기다릴 것인지
비동기 복제
- 복제 이벤트를 전달만 할 뿐 응답을 확인하지 않음
- 복제 이벤트 전파를 확인하지 않고 변경 저장
반동기 복제
- 복제 이벤트를 전달하고 relay log에 쓰여지는 것을 확인
- 복제 이벤트 전파가 relay log에 전파되는 것을 확인 후 변경 저장
- 복제가 '완료'될 때까지 기다리지 않음
결론
- 데이터베이스가 자꾸 죽는다면 예비 서버 구축 구상
- 복제 지연 간극을 줄이고 싶다며 비동기 복제 -> 반동기 복제로 변경 시도
- 소스 서버에서 레플리카로 복제되지 않는다면 바이너리 로그 덤프 스레드를 확인
- 레거시 시스템의 복제 타입이 파일 위치 기반이라면 소스 서버 장애에 대응하도록 GTID로 변경 시도
추가 학습 내용
- 데이터베이스의 가용성이 필요할 때 언제 스케일 아웃하고 언제 스케일업?
- 레플리카 서버와 소스 서버의 적절한 개수?
- 복제 시스템 구축 방법?
- 복제 지연의 위험성과 해결 방안?
- 복제 지연을 일부로 해결하지 않을 때(knowned issue)의 경우는?
- Sharding과 Partitioning 그리고 Replication의 차이점은?
'CS' 카테고리의 다른 글
| [테코톡] CSR과 SSR (0) | 2025.04.03 |
|---|---|
| [테코톡] MySQL 옵티마이저의 실행계획 (0) | 2025.03.27 |